สรุปโดยย่อ
- ARC-AGI-3 เปิดเผยช่องว่างขนาดใหญ่ระหว่างคำอ้างถึง AGI กับความเป็นจริง โดยโมเดล AI ชั้นนำมีคะแนนต่ำกว่า 1% ในขณะที่มนุษย์ทำได้สมบูรณ์แบบ
- การทดสอบนี้เป็นการวัดความสามารถในการทั่วไปที่แท้จริง—ต้องให้เอเจนต์สำรวจ วางแผน และเรียนรู้จากศูนย์ในสภาพแวดล้อมที่ไม่รู้จัก แทนที่จะจำรูปแบบที่ฝึกมาแล้ว
- แม้จะมีการโฆษณาในอุตสาหกรรม ระบบ AI ปัจจุบันยังห่างไกลจาก AGI มาก ขาดความสามารถในการคิดวิเคราะห์และปรับตัวที่แม้แต่เด็กมนุษย์ก็แสดงออกตามธรรมชาติ
ซีอีโอ Nvidia Jensen Huang ไปออกรายการพอดแคสต์ของ Lex Fridman เมื่อสัปดาห์ที่แล้วและกล่าวอย่างชัดเจนว่า “ผมคิดว่าเราได้บรรลุ AGI แล้ว” สองวันต่อมา การทดสอบที่เข้มงวดที่สุดในวงการ AI ก็ปล่อยเกณฑ์วัดความสามารถด้านปัญญาประดิษฐ์ทั่วไปเวอร์ชันใหม่—และโมเดลทุกตัวทำคะแนนต่ำกว่า 1%
มูลนิธิ ARC Prize ได้ปล่อย ARC-AGI-3 ในสัปดาห์นี้ ผลลัพธ์รุนแรงมาก Gemini 3.1 Pro ของ Google นำที่ 0.37% GPT-5.4 ของ OpenAI ได้ 0.26% Claude Opus 4.6 ของ Anthropic ทำได้ 0.25% ขณะที่ Grok-4.20 ของ xAI ทำได้คะแนนเป็นศูนย์ ในขณะที่มนุษย์แก้ปัญหาได้ 100% ของสภาพแวดล้อม
นี่ไม่ใช่การทดสอบความรู้ทั่วไปหรือแบบทดสอบเขียนโค้ด หรือแม้แต่คำถามระดับปริญญาเอกที่ยากมาก ARC-AGI-3 เป็นสิ่งที่แตกต่างอย่างสิ้นเชิงจากสิ่งที่อุตสาหกรรม AI เคยเผชิญมาก่อน
เกณฑ์นี้สร้างโดยมูลนิธิของ François Chollet และ Mike Knoop ซึ่งตั้งสตูดิโอเกมภายในและสร้างสภาพแวดล้อมแบบโต้ตอบ 135 แบบขึ้นมาเอง แนวคิดคือการปล่อยให้ AI เข้าไปในโลกเสมือนเกมที่ไม่คุ้นเคย โดยไม่มีคำแนะนำ ไม่มีเป้าหมายชัดเจน และไม่มีคำอธิบายกติกา เอเจนต์ต้องสำรวจ ค้นหาว่าต้องทำอะไร วางแผน และลงมือทำ
ถ้านั่นฟังดูเหมือนอะไรที่เด็กอายุห้าขวบทำได้ คุณก็เริ่มเข้าใจปัญหาแล้ว ถ้าคุณอยากรู้ว่าคุณเก่งกว่า AI หรือไม่ ก็สามารถเล่นเกมเดียวกับที่ใช้ในการทดสอบนี้ได้โดยคลิกที่ลิงก์นี้ เราลองเล่นหนึ่งเกม มันแปลกในตอนแรก แต่หลังจากผ่านไปไม่กี่วินาที คุณก็สามารถเข้าใจมันได้ง่าย
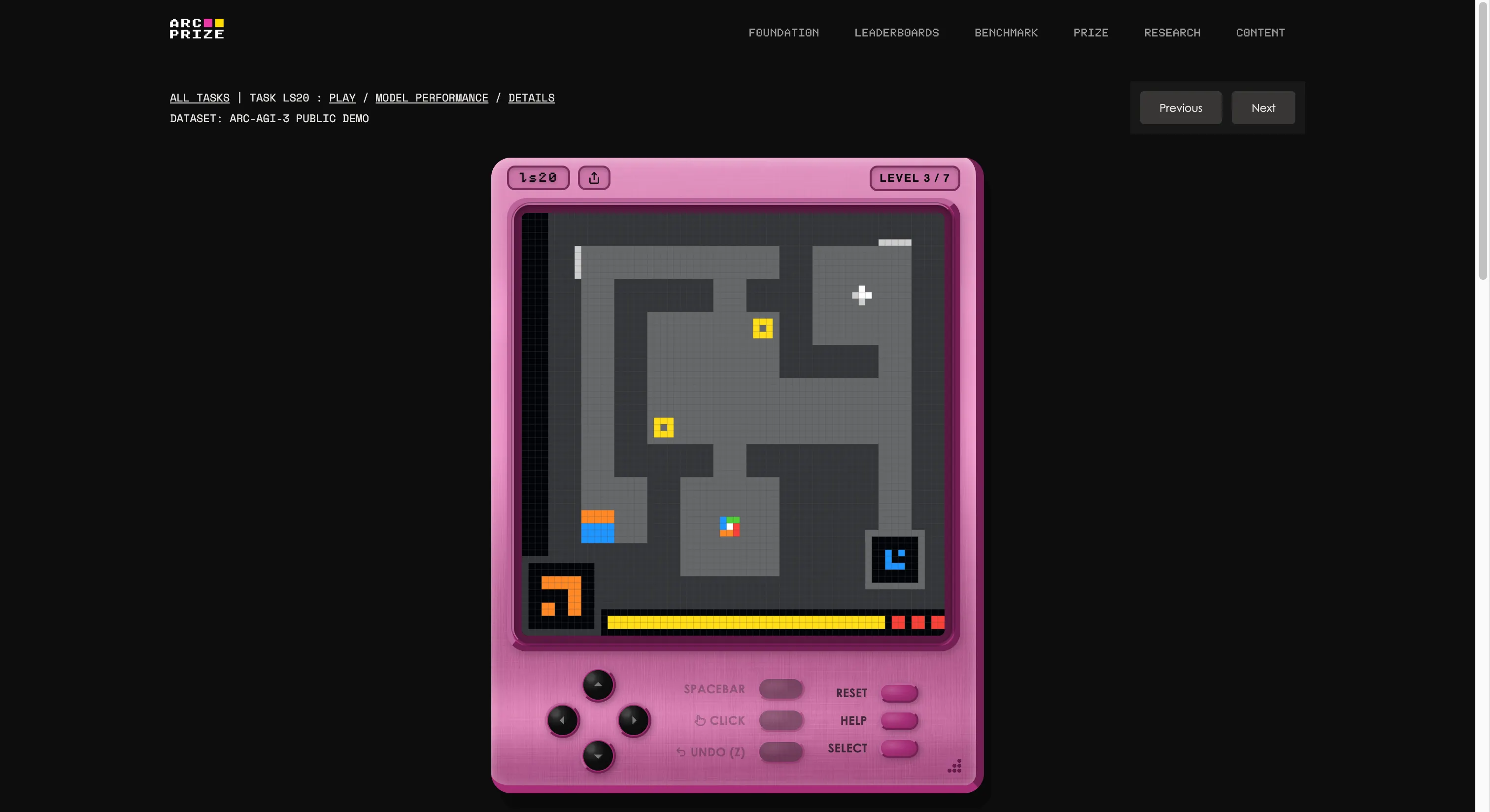
นอกจากนี้ยังเป็นตัวอย่างที่ชัดเจนที่สุดของสิ่งที่คำว่า “G” ใน AGI หมายถึง เมื่อคุณสามารถสร้างความรู้ใหม่ (วิธีการทำงานของเกมแปลกๆ) โดยไม่ต้องฝึกฝนล่วงหน้า
เวอร์ชันก่อนหน้าของ ARC ทดสอบปริศนาภาพนิ่งแบบคงที่—แสดงแพทเทิร์นแล้วทายว่าต่อไปจะเป็นอะไร ซึ่งตอนแรกก็ยากมาก จากนั้นห้องทดลองก็ใช้พลังการคำนวณและการฝึกฝนจนเกณฑ์วัดกลายเป็นเรื่องง่าย ARC-AGI-1 ซึ่งเปิดตัวในปี 2019 ล้มเหลวในการทดสอบด้วยโมเดลที่เน้นการฝึกฝนและการวิเคราะห์ ARC-AGI-2 อยู่ได้ประมาณหนึ่งปี ก่อนที่ Gemini 3.1 Pro จะทำได้ 77.1% ห้องทดลองเก่งมากในการเติมเต็มเกณฑ์วัดที่สามารถฝึกได้
เวอร์ชัน 3 ถูกออกแบบมาโดยเฉพาะเพื่อป้องกันไม่ให้เป็นเช่นนั้น โดยเก็บสภาพแวดล้อมไว้เป็นความลับ 110 จาก 135 สภาพแวดล้อม—55 แบบกึ่งส่วนตัวสำหรับทดสอบ API และอีก 55 แบบล็อคเต็มสำหรับการแข่งขัน—จึงไม่มีชุดข้อมูลให้จดจำ คุณไม่สามารถบังคับให้ AI ผ่านกฎเกมใหม่ที่ไม่เคยเห็นมาก่อนได้ง่ายๆ
การให้คะแนนก็ไม่ใช่แค่ผ่าน/ไม่ผ่าน ARC-AGI-3 ใช้เกณฑ์ที่มูลนิธิเรียกว่า RHAE—ประสิทธิภาพการดำเนินการของมนุษย์เปรียบเทียบเชิงสัมพันธ์ จุดอ้างอิงคือผลการทำงานของมนุษย์ที่ดีที่สุดเป็นอันดับสองในรอบแรก โมเดล AI ที่ใช้ Actions มากกว่ามนุษย์สิบเท่าจะได้คะแนนเพียง 1% สำหรับระดับนั้น ไม่ใช่ 10% สูตรจะยกกำลังโทษความไร้ประสิทธิภาพ การเดินวนไปวนมา การย้อนกลับ และการเดาเพื่อหาคำตอบจะถูกลงโทษอย่างรุนแรง
เอเจนต์ AI ที่ดีที่สุดในช่วงพรีวิวหนึ่งเดือนของนักพัฒนาทำได้ 12.58% ในขณะที่โมเดล LLMs ที่ทดสอบผ่าน API อย่างเป็นทางการ โดยไม่มีเครื่องมือพิเศษใดๆ ก็ไม่สามารถทำคะแนนเกิน 1% ได้ มนุษย์ธรรมดาแก้ปัญหาได้ครบทั้ง 135 สภาพแวดล้อมโดยไม่ต้องฝึกฝนล่วงหน้าและไม่มีคำแนะนำ ถ้านั่นคือมาตรฐาน ระบบปัจจุบันก็ยังไม่ผ่าน
ยังมีข้อถกเถียงทางวิธีการอยู่บ้าง รายงานของ ARC ระบุว่า การใช้เครื่องมือที่สร้างขึ้นโดย Duke ช่วยให้ Claude Opus 4.6 จาก 0.25% ไปถึง 97.1% ในสภาพแวดล้อมเดียวที่เรียกว่า TR87 ซึ่งไม่ได้หมายความว่า Claude ทำคะแนน 97.1% ในภาพรวมของ ARC-AGI-3 แต่คะแนนอย่างเป็นทางการยังคงอยู่ที่ 0.25% แต่การเปลี่ยนแปลงนี้ก็เป็นสิ่งที่น่าสนใจ
เกณฑ์วัดอย่างเป็นทางการให้เอเจนต์รับข้อมูลเป็นโค้ด JSON ไม่ใช่ภาพ นั่นอาจเป็นข้อบกพร่องทางวิธีการ หรือเป็นการแสดงให้เห็นว่าโมเดลในปัจจุบันทำงานได้ดีขึ้นในการประมวลผลข้อมูลที่เป็นมิตรกับมนุษย์มากกว่าข้อมูลแบบโครงสร้างดิบ มูลนิธิของ Chollet ยอมรับข้อถกเถียงนี้ แต่ก็ไม่เปลี่ยนแปลงรูปแบบ
“การรับรู้เนื้อหาภาพและรูปแบบ API ไม่ใช่ปัจจัยจำกัดสำหรับประสิทธิภาพของโมเดลระดับแนวหน้าใน ARC-AGI-3” เอกสารระบุ กล่าวอีกนัยหนึ่ง พวกเขาดูเหมือนจะปฏิเสธแนวคิดที่ว่าโมเดลล้มเหลวเพราะ “มองไม่เห็น” งานอย่างถูกต้อง แต่กลับเชื่อว่าการรับรู้ในปัจจุบันเพียงพอแล้ว—ช่องว่างที่แท้จริงอยู่ที่การคิดวิเคราะห์และการทั่วไป
การตรวจสอบความเป็นจริงของ AGI เกิดขึ้นในช่วงที่กระแสความคาดหวังพุ่งสูงสุด นอกจากคำพูดของ Huang แล้ว Arm ก็ตั้งชื่อชิปศูนย์ข้อมูลใหม่ว่า “AGI CPU” Sam Altman จาก OpenAI กล่าวว่าพวกเขา “สร้าง AGI ขึ้นมาแล้วเป็นพื้นฐาน” และ Microsoft ก็เริ่มทำการตลาดห้องปฏิบัติการที่เน้นสร้าง ASI: พัฒนาการต่อยอดจากความสำเร็จของ AGI คำว่านี้ถูกบิดเบือนจนกลายเป็นคำที่หมายความตามความสะดวกทางการค้า
ตำแหน่งของ Chollet ก็ง่ายขึ้น ถ้าคนธรรมดาที่ไม่มีคำแนะนำสามารถทำได้ แต่ระบบของคุณทำไม่ได้ ก็แปลว่าคุณยังไม่มี AGI—คุณมีแค่ระบบเติมคำอัตโนมัติราคาสูงที่ต้องการความช่วยเหลือมาก
รางวัล ARC Prize 2026 มอบเงิน 2 ล้านดอลลาร์ในสามสายการแข่งขัน ซึ่งจัดบน Kaggle ทุกโซลูชันที่ชนะต้องเปิดซอร์ส โอกาสกำลังหมดเวลา และตอนนี้ ระบบยังห่างไกลจากความเป็นจริงมาก
