
The AI memory system MemPalace, developed with the participation of Milla Jovovich, claimed a perfect score in testing and quickly went viral—only to be exposed by the community for allegedly cheating in the tests and misleading data. Real-world testing found that the results were exaggerated and there were many errors. The team has admitted the flaws and is working on fixes.
Milla Jovovich builds an AI memory palace, drawing attention from the outside world
Yesterday (4/7), there was a big news in the AI circle: Hollywood star Milla Jovovich (famous for Resident Evil and The Fifth Element), together with developer Ben Sigman, used Claude Code to assist development of the open-source AI memory system “MemPalace.”
For a time, the claim that “a Hollywood superstar crossed over to deliver a perfect-scoring project” spread widely. To date, MemPalace has also received more than 20k stars on GitHub, but it didn’t take long for the developer community to raise questions: Is there really substance, or is it just hype?
First, let’s talk about the motivation behind MemPalace’s creation. Official documentation says it aims to solve the problem that, in current AI systems, the content of user-AI conversations, the decision-making process, and architecture discussions typically disappear after a work session ends—leading to the loss of months of effort as memory “drops to zero.”
To solve this issue, MemPalace uses a spatial architecture to store memories, clearly categorizing information into wing areas representing people or projects, as well as into different levels of structure such as corridors, rooms, and drawers, preserving the original dialogue text for later semantic search.
The development team claims that MemPalace achieved a perfect score of 100% in the long-term memory evaluation benchmark LongMemEval, and reached 96.6% accuracy without calling any external API. It can run fully locally without needing to subscribe to cloud services, and it is also equipped with an AAAK dialect system that claims to achieve 30x lossless compression.
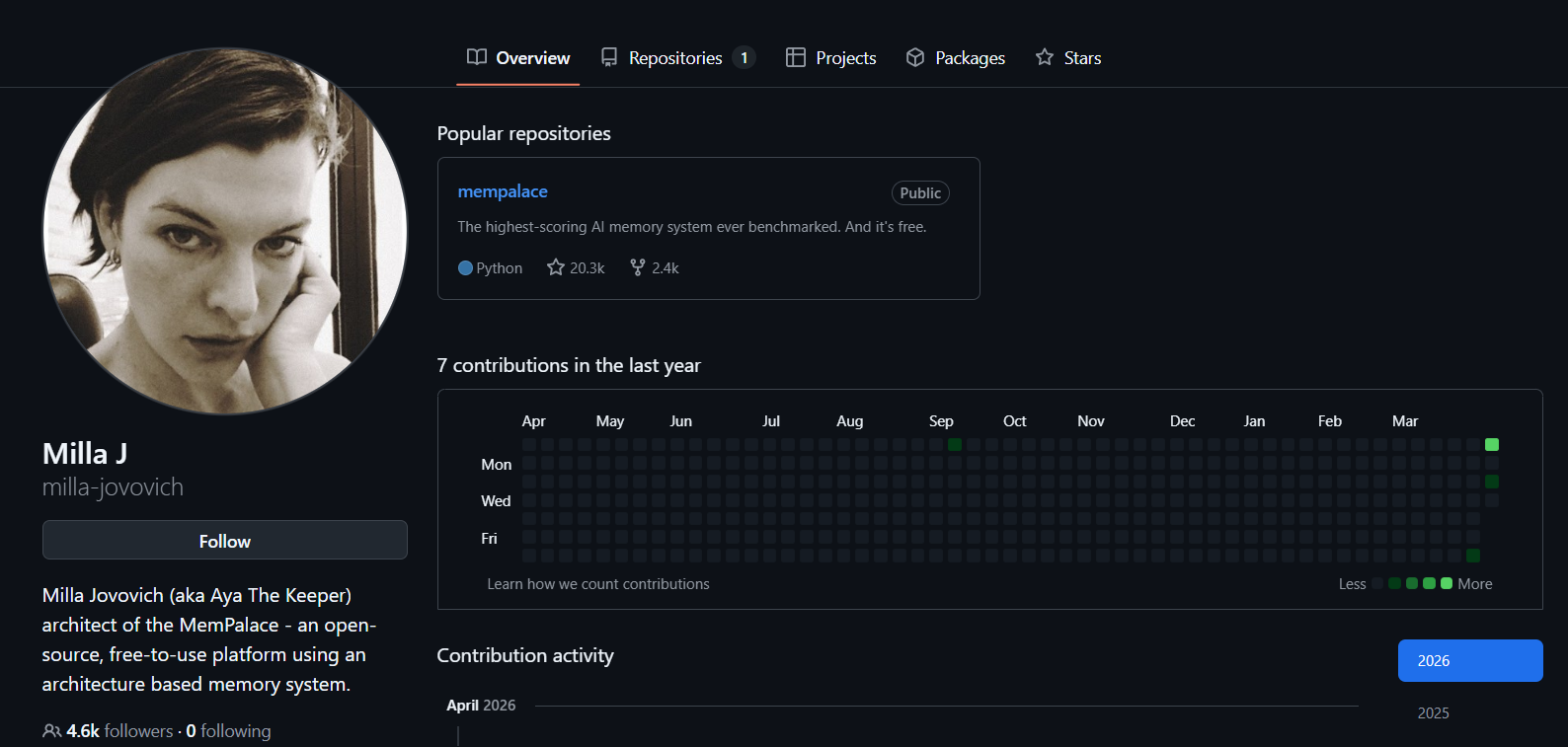
Image source: GitHub Hollywood star Milla Jovovich builds an AI memory palace, drawing attention from the outside world
Peers and the community all question it; the testing method and marketing have shortcomings
However, MemPalace’s claimed perfect score on LongMemEval soon drew skepticism from peers.
PenfieldLabs, which also develops AI memory systems, pointed out that MemPalace’s claimed perfect results on the LoCoMo dataset are mathematically impossible, because the dataset’s standard answers themselves already include 99 incorrect items.
PenfieldLabs’ analysis found that MemPalace’s 100% score came from setting the retrieval count to 50 times, but the dialogue traces in the test dataset had only a maximum of 32 stages. This means the system effectively bypasses the retrieval stage and hands all data to the AI model to read.
Regarding the 100% score on LongMemEval, the development team was found to have made changes for three specific problems that were concentrated during development, writing dedicated patch code—raising suspicion of cheating on the test set.

Image source: Reddit Peers PenfieldLabs pointed out that it’s mathematically impossible for MemPalace to achieve a perfect score on the LoCoMo dataset
Real-world testing by GitHub users; the benchmark contains misleading elements
After testing, GitHub user hugooconnor commented that while MemPalace claims a retrieval accuracy as high as 96.6%, in practice it didn’t use the MemPalace-branded memory palace architecture at all. hugooconnor said that their test simply calls the default functionality of the underlying database ChromaDB, with no involvement of the categorization logic of wing areas, rooms, or drawers emphasized by the project.
hugooconnor found that when the system truly enables these exclusive memory-palace classification logics, retrieval performance instead drops. For example, in room mode, accuracy falls to 89.4%, and after enabling AAAK compression technology, accuracy drops further to 84.2%—both are lower than the default database performance.
hugooconnor also criticized the testing method. In MemPalace’s testing environment, the retrieval range for each question is deliberately narrowed to about 50 dialogue stages, making it too easy to find answers in an extremely small sample library.
If the range is expanded to more than 19,000 dialogue stages in real scenarios, the accuracy of traditional keyword search would plummet to 30%, indicating that MemPalace’s current testing approach is hiding the real difficulty of searching.
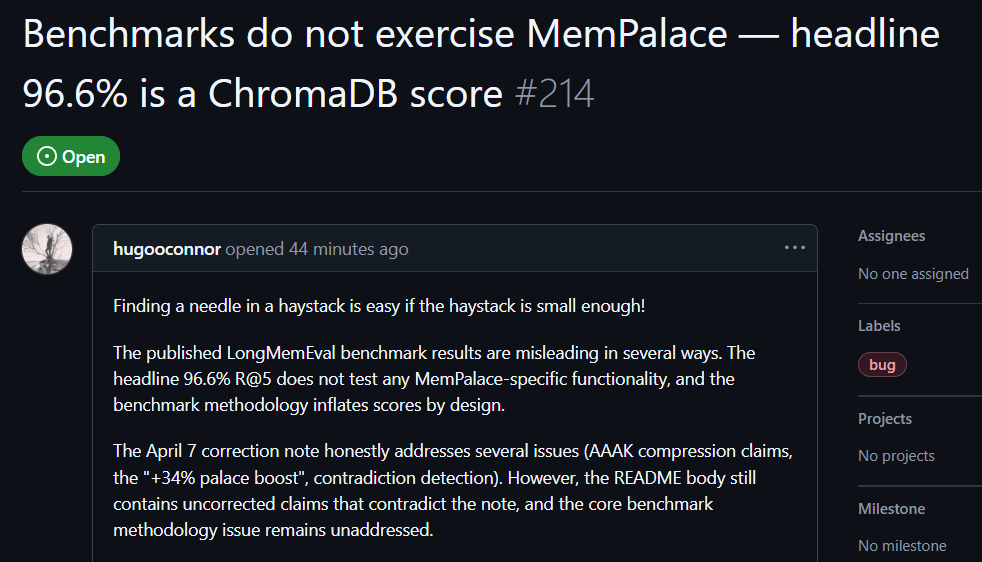
Image source: GitHub GitHub users’ real-world testing shows that MemPalace’s benchmark contains misleading elements
Meanwhile, although the development team has already issued a correction statement, admitting that AAAK technology was indeed verified as lossy compression and promising to revise the documentation and system design based on the community’s harsh criticisms, the project’s main description still retains multiple exaggerated claims that have not been corrected. These include claims of 30x lossless compression and a 34% retrieval improvement, and the comparison charts with other competitors also completely lack sources.
MemPalace original code faces multiple Bugs
As more and more developers download and test it, many bug reports about MemPalace’s source code have appeared on GitHub.
User cktang88 listed multiple serious issues, including compression commands that can’t run and cause the system to crash, errors in the logic that calculates the number of summary words, inaccurate statistical data for digging rooms, and the server loading all embedded interpretation data into memory on every call—leading to severe resource consumption problems.
Other issues pointed out also include the system hard-coding developers’ family member names into the default configuration file, as well as a forced display limit of 10k records when querying status.
For these problems, the open-source community has already begun to actively fix them. User adv3nt3 submitted multiplefix requests, including correcting the digging statistics data, removing the default family member names, and delaying the initialization time of the knowledge graph. The development team later also admitted these errors and is gradually resolving code issues through community collaboration.
Milla Jovovich’s Vibe Coding is cool; the marketing isn’t
Regarding the MemPalace project, Hacker News user darkhanakh reached a conclusion: MemPalace gives off a sense of OpenClaw—that is, it artificially manipulates benchmark results to make them look flawless, and then packages it as some kind of major breakthrough for marketing.
He believes the underlying technology of MemPalace may indeed be interesting, but with testing methods that have such shortcomings, and then also promoting it with “the highest public score in history,” it just isn’t appropriate. “However, the fact that Milla Jovovich is playing Vibe Coding—I still think that’s pretty cool.”
Further reading:
AI writes code and messes up! The convenience store “best-by-date” app “Food-Saving Hunter” explodes with security issues; your home GPS is exposed naked
