出典: 新志源 画像ソース: Unbounded AI によって生成最近、IBM は、最新の 14nm アナログ AI チップを発売しました。これは、主要な GPU よりも 14 倍効率が高く、H100 にお金を払う価値があります。 用紙のアドレス:現在、生成型 AI の開発における最大の障害は、その驚くべき消費電力です。 AI に必要なリソースは持続的に成長することができません。一方、IBMはAIコンピューティングを再構築する方法を研究してきた。彼らの成果の 1 つは、生物学的な脳内で実行されるニューラル ネットワークの主要な機能を使用してエネルギー消費を削減できる、模擬メモリ コンピューティング/模擬人工知能手法です。このアプローチにより、計算に費やす時間と労力が最小限に抑えられます。Nvidia の独占は覆されようとしていますか? ## **AI の未来に向けた IBM の最新の青写真: アナログ AI チップはエネルギー効率が 14 倍優れています**海外メディアInsiderの報道によると、半導体調査会社セミアナリシスの首席アナリスト、ディラン・パテル氏は、ChatGPTの1日の運用コストが70万ドルを超えていると分析した。ChatGPT は、ユーザーのプロンプトに基づいて回答を生成するために多くのコンピューティング能力を必要とします。コストのほとんどは高価なサーバーで発生します。将来的には、モデルのトレーニングとインフラストラクチャの運用にかかるコストはますます高騰するでしょう。 IBMは、この新しいチップがエネルギー消費を削減することで、MidjourneyやGPT-4などの生成AI企業の構築と運営のプレッシャーを軽減できるとNatureに発表した。これらのアナログ チップは、アナログ信号を操作して 0 と 1 の間の勾配を理解できるデジタル チップとは異なる方法で構築されていますが、異なるバイナリ信号のみを認識します。### **シミュレートされたメモリ コンピューティング/シミュレートされた AI**そして、IBM の新しいアプローチは、メモリ コンピューティング、略して AI をシミュレートすることです。生物学的な脳で動作するニューラル ネットワークの重要な機能を利用することで、エネルギー消費を削減します。人間や他の動物の脳では、シナプスの強さ(または「重さ」)がニューロン間の通信を決定します。アナログ AI システムの場合、IBM はこれらのシナプスの重みをナノメートルスケールの抵抗メモリデバイス (相変化メモリ PCM など) のコンダクタンス値に保存し、回路の法則を使用してメモリとメモリの間でデータを常に送信する必要性を減らします。プロセッサは、DNN の主要な演算である積和演算 (MAC) 演算を実行します。現在、多くの生成 AI プラットフォームを支えているのは、Nvidia の H100 と A100 です。しかし、IBMがチップのプロトタイプを繰り返し、大衆市場への投入に成功すれば、この新しいチップがNvidiaに取って代わる新たな主力となる可能性は十分にあります。 この 14nm アナログ AI チップは、コンポーネントごとに 3,500 万個の相変化メモリ デバイスをエンコードでき、最大 1,700 万個のパラメータをシミュレートできます。また、このチップは人間の脳の仕組みを模倣しており、マイクロチップがメモリ内で直接計算を実行します。このチップのシステムは、デジタル ハードウェアに近い精度で、効率的な音声認識と転写を実現できます。このチップは約 14 倍の性能を達成しており、以前のシミュレーションでは、このハードウェアのエネルギー効率は今日の主要な GPU の 40 倍から 140 倍であることが示されています。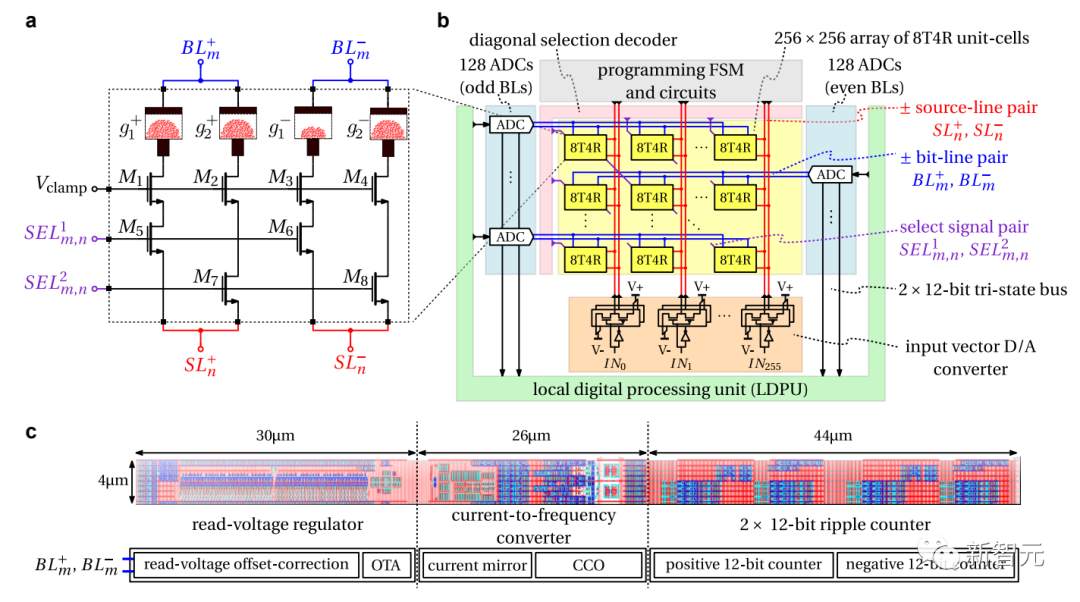 PCM クロスバー アレイ、プログラミング、デジタル信号処理この生成 AI 革命はまだ始まったばかりです。ディープ ニューラル ネットワーク (DNN) は AI 分野に革命をもたらし、基本モデルと生成 AI の開発によって注目を集めてきました。ただし、これらのモデルを従来の数学的コンピューティング アーキテクチャで実行すると、パフォーマンスとエネルギー効率が制限されます。AI 推論用のハードウェアの開発は進んでいますが、これらのアーキテクチャの多くはメモリと処理ユニットを物理的に分離しています。これは、AI モデルが通常、個別のメモリの場所に保存され、コンピューティング タスクではメモリと処理ユニットの間でデータを絶えずシャッフルする必要があることを意味します。このプロセスにより計算が大幅に遅くなり、達成できる最大のエネルギー効率が制限される可能性があります。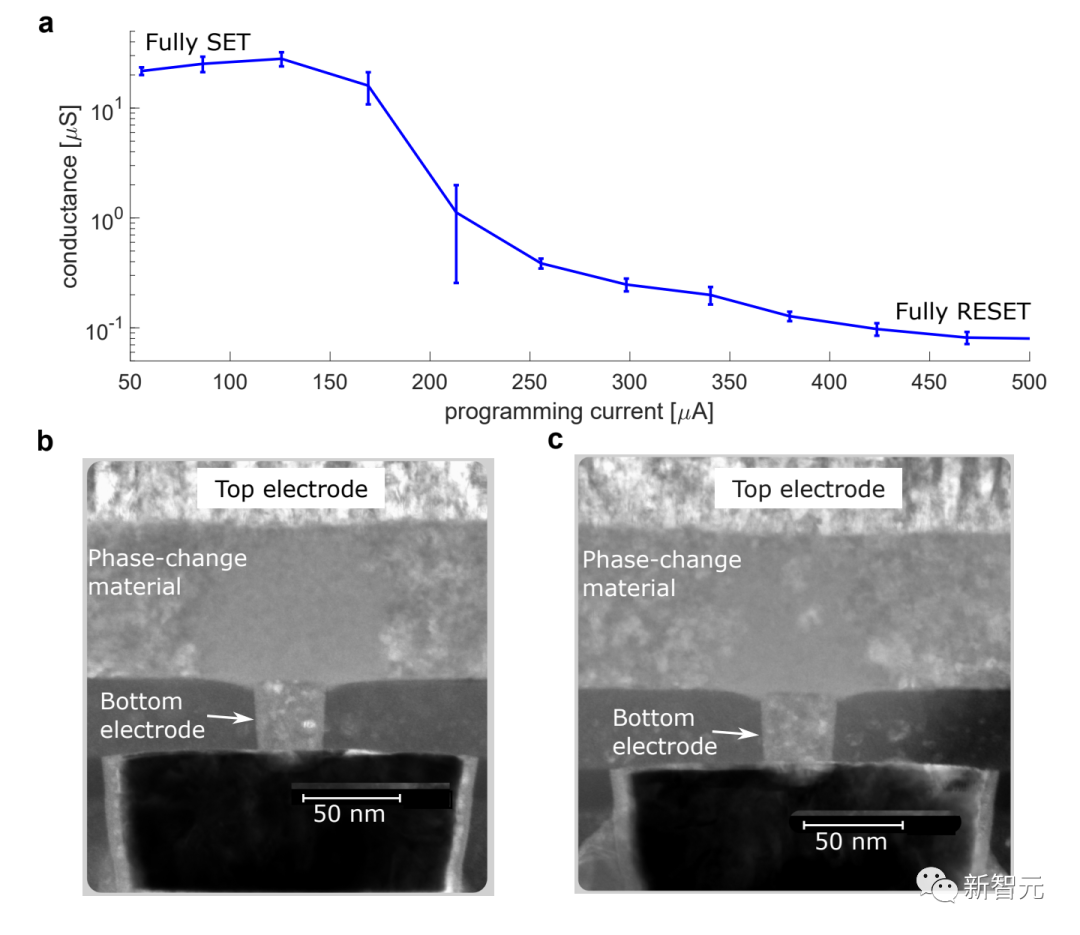 位相構成とアドミタンスを使用してアナログ形式のシナプス重みを保存する PCM デバイスのパフォーマンス特性IBM の相変化メモリ (PCM) ベースの人工知能加速チップは、この制限を取り除きます。相変化メモリ (PCM) は、計算と記憶の統合を実現し、メモリ内で行列とベクトルの乗算を直接実行できるため、データ転送の問題を回避できます。同時に、IBMのアナログAIチップは、ハードウェアレベルのコンピューティングとストレージの統合を通じて効率的な人工知能推論の高速化を実現しており、これはこの分野における重要な進歩である。## **AI のシミュレーションにおける 2 つの主要な課題**シミュレートされた AI の概念を実現するには、次の 2 つの重要な課題を克服する必要があります。1. メモリ アレイの計算精度は、既存のデジタル システムの計算精度に匹敵する必要があります。2. メモリ アレイは、他のデジタル コンピューティング ユニットおよびアナログ人工知能チップ上のデジタル通信構造とシームレスにインターフェイスできます。IBM は、アルバニー ナノにあるテクノロジー センターで相変化メモリ ベースの人工知能アクセラレータ チップを製造しています。このチップは 64 個のアナログ メモリ コンピューティング コアで構成され、各コアには 256×256 個のクロスストリップ シナプス ユニットが含まれています。また、各チップには、アナログ世界とデジタル世界の間で変換するためのコンパクトな時間ベースのアナログ - デジタル コンバーターが統合されています。チップ内の軽量デジタル処理ユニットは、単純な非線形ニューロン活性化関数とスケーリング操作も実行できます。各コアは、ディープ ニューラル ネットワーク (DNN) モデルの層 (畳み込み層など) に関連付けられた行列ベクトル乗算やその他の操作を実行できるタイルと考えることができます。重み行列は、PCM デバイスのシミュレートされたコンダクタンス値にエンコードされ、オンチップに保存されます。グローバル デジタル処理ユニットはチップのコア アレイの中央に統合されており、特定の種類のニューラル ネットワーク (LSTM など) の実行にとって重要な行列ベクトル乗算よりも複雑な演算を実装します。デジタル通信パスは、コア間およびコアとグローバル ユニット間のデータ転送のために、すべてのコアとグローバル デジタル処理ユニットの間でオンチップに統合されています。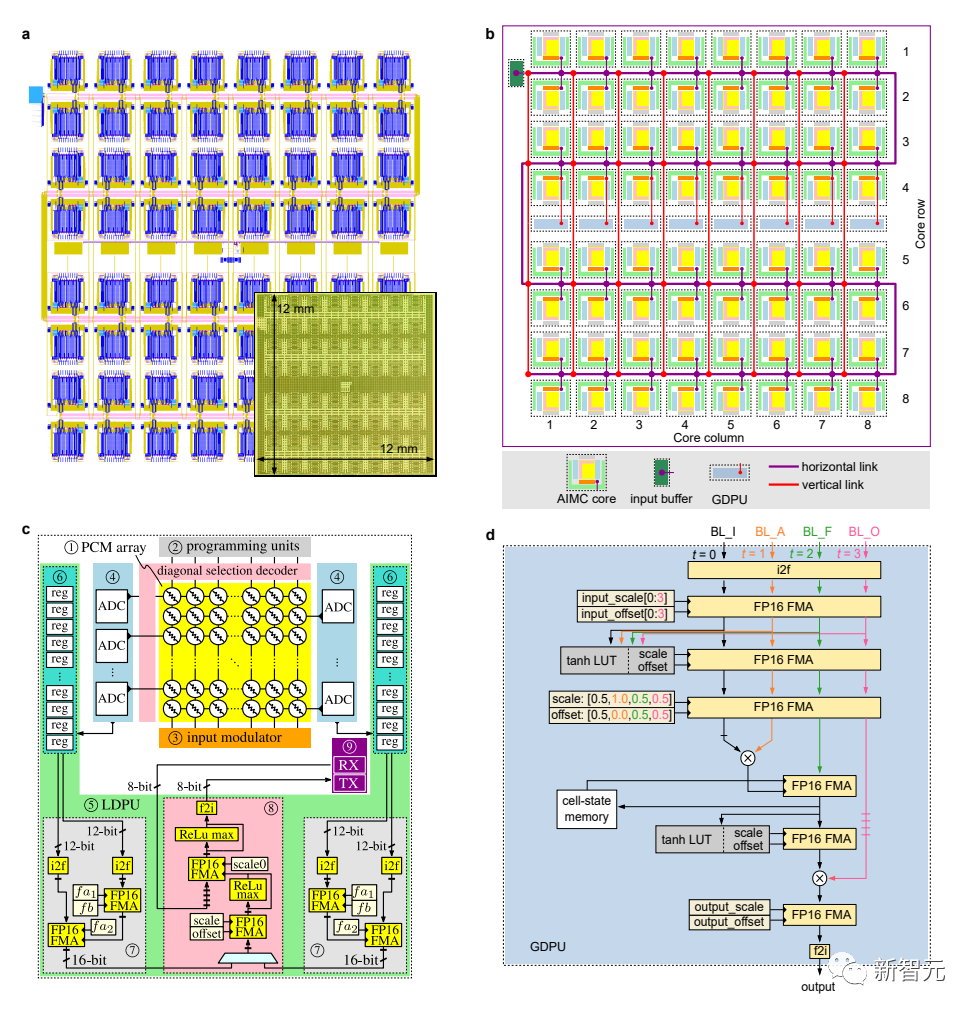 a: 電子設計自動化のスナップショットとチップの顕微鏡写真。64 個のコアと 5616 個のパッドが確認できます。b: 64 コア、8 つのグローバル デジタル プロセッシング ユニット、コア間のデータ リンクを含む、チップのさまざまなコンポーネントの概略図c: 単一の PCM ベースのインメモリ コンピューティング コアの構造d: LSTM 関連計算のためのグローバルデジタル処理ユニットの構造このチップを使用して、IBM はアナログ メモリ コンピューティングの計算精度に関する包括的な研究を実施し、CIFAR-10 画像データセットで 92.81% の精度を達成しました。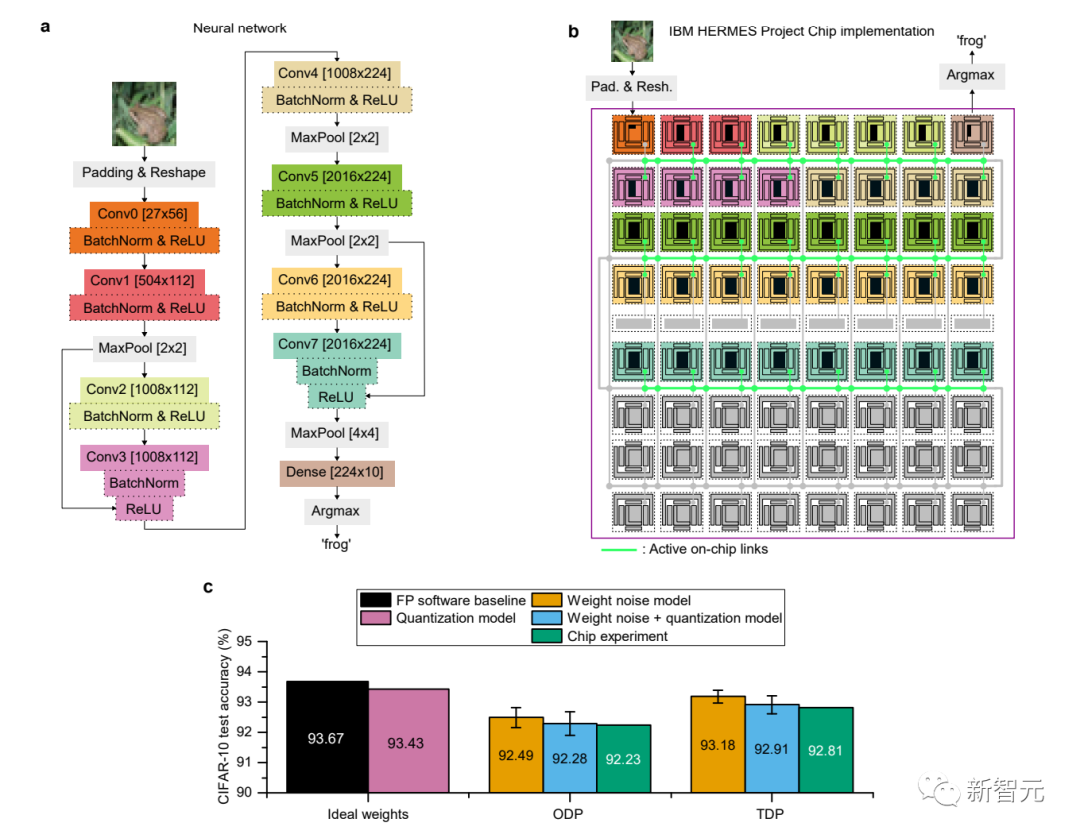 a: CIFAR-10 の ResNet-9 ネットワーク構造b: このネットワークをチップ上にマッピングする方法c: ハードウェア実装の CIFAR-10 テスト精度これは、同様のテクノロジーを使用したチップとしてこれまでに報告されている最高の精度です。IBM はまた、アナログ インメモリ コンピューティングと複数のデジタル処理装置およびデジタル通信構造をシームレスに組み合わせます。このチップの 8 ビット入出力行列乗算の単位面積スループットは 400 GOPS/mm2 で、これは抵抗メモリに基づく以前のマルチコア メモリ コンピューティング チップよりも 15 倍以上高く、同時にかなりのエネルギー効率も達成します。文字予測タスクと画像アノテーション生成タスクにおいて、IBMはハードウェア上で測定した結果を他の方法と比較し、シミュレートされたAIチップ上で実行される関連タスクのネットワーク構造、重み付けプログラミング、および測定結果を実証しました。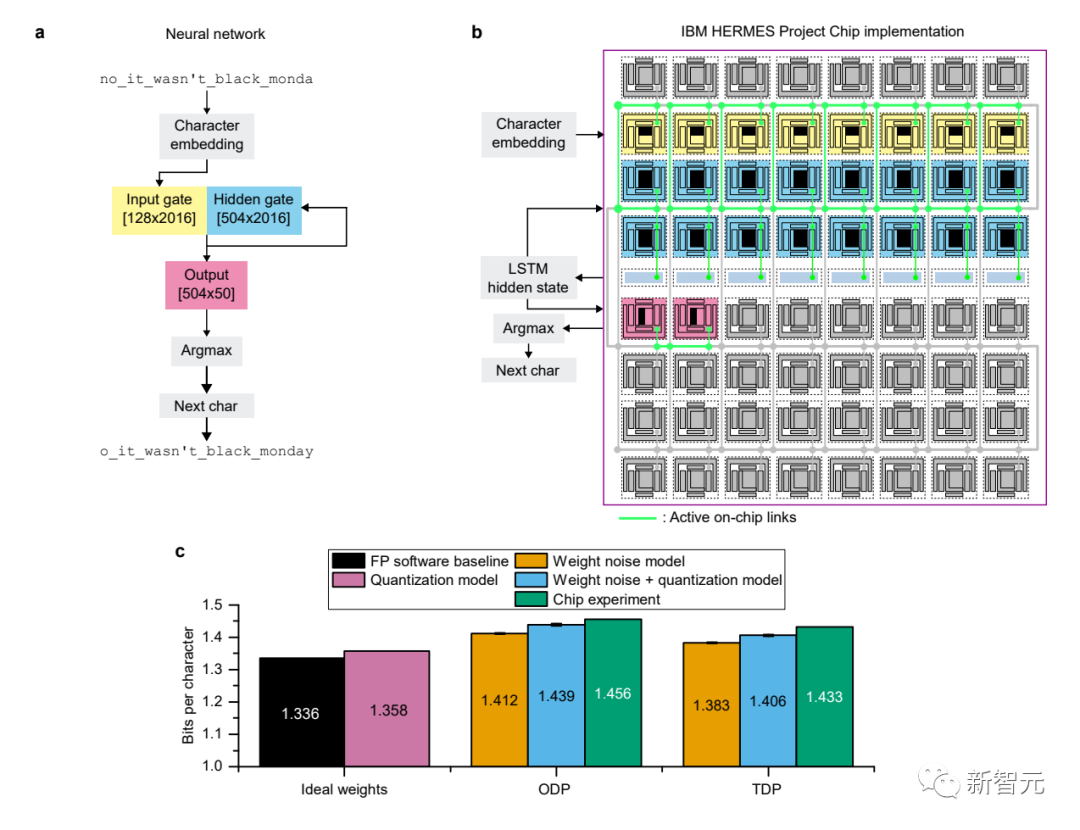 文字予測のためのLSTM測定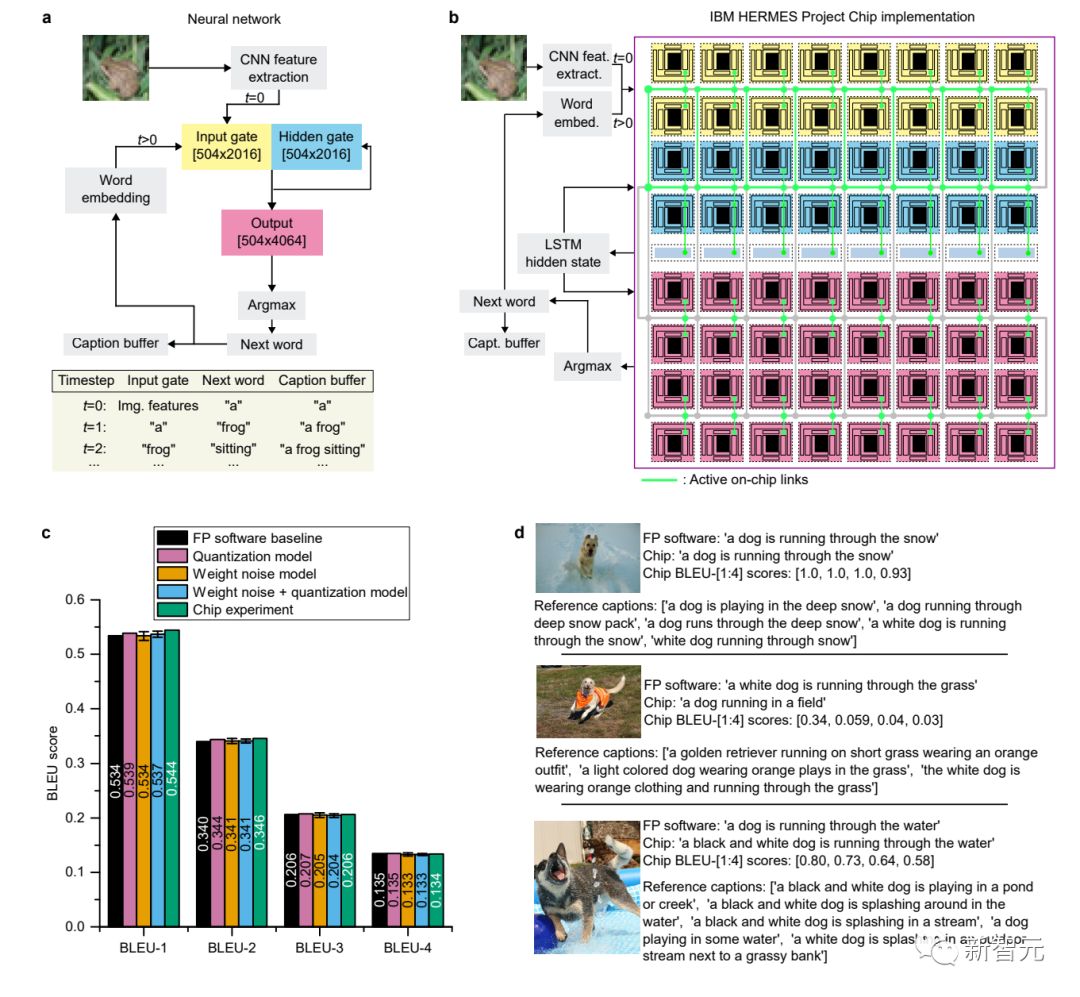 画像アノテーション生成のための LSTM ネットワーク測定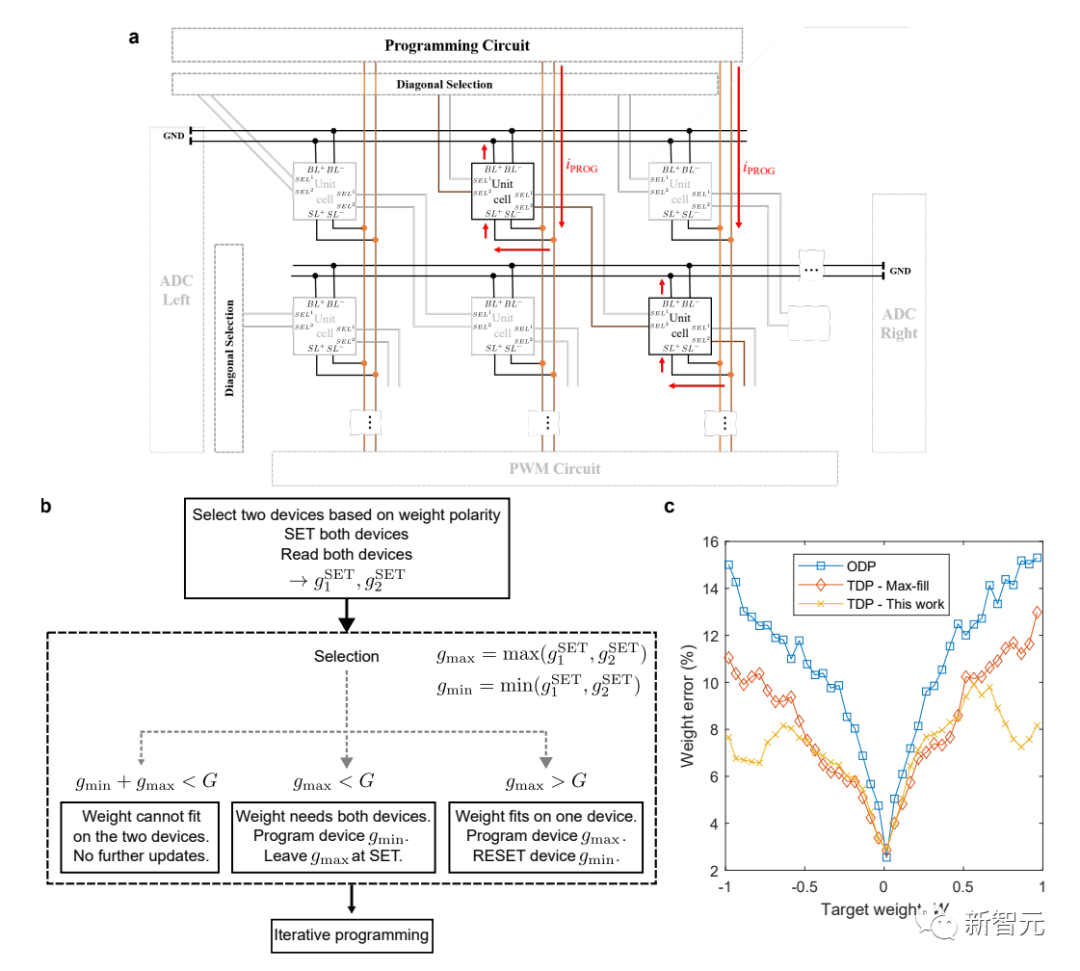 ウェイトプログラミングプロセス**NVIDIA の堀は底なし? **Nvidia の独占はそんなに簡単に崩れるのでしょうか?ナヴィーン・ラオは、神経科学から転向したテクノロジー起業家で、世界有数の人工知能メーカーである Nvidia と競争しようとしました。「誰もが Nvidia で開発を行っています。新しいハードウェアを発売したい場合は、Nvidia に追いつき、競争する必要があります。」とラオ氏は述べました。ラオ氏は、インテルが買収した新興企業で Nvidia の GPU を置き換えるように設計されたチップの開発に取り組んでいましたが、Intel を辞めた後は、自身が率いるソフトウェア スタートアップ企業 MosaicML で Nvidia のチップを使用しました。Rao 氏は、Nvidia はチップ上で他の製品との大きな差を広げただけでなく、AI プログラマーの大規模なコミュニティを創設することでチップの外側でも差別化を達成したと述べました。AI プログラマーは同社のテクノロジーを活用して革新を続けています。 Nvidia は 10 年以上にわたり、画像、顔、音声認識などの複雑な AI タスクを実行したり、ChatGPT などのチャットボット用のテキストを生成したりできるチップの製造において、ほぼ確実なリードを築いてきました。かつて業界の新興企業だった同社が AI チップ製造分野で優位性を達成できたのは、AI のトレンドを早くから認識し、それらのタスク用にカスタム構築したチップを開発し、AI 開発を促進する重要なソフトウェアを開発したためです。それ以来、Nvidia の共同創設者兼 CEO の Jensen Huang は、Nvidia の水準を引き上げてきました。 これにより、Nvidia は AI 開発のワンストップ サプライヤーになります。Google、Amazon、Meta、IBMなどもAIチップを製造しているが、調査会社Omdiaによると、現在AIチップの売上高の70%以上をNvidiaが占めているという。今年6月、NVIDIAの市場価値は1兆ドルを超え、世界で最も価値のあるチップメーカーとなった。 FuturumGroupのアナリストは「顧客は新興企業や他の競合他社から既製のチップを購入する代わりに、Nvidiaシステムを購入するのに18カ月も待つだろう。これは信じられないことだ」と述べた。**NVIDIA、コンピューティング手法を再構築**###ジェンセン フアンは 1993 年に Nvidia を共同設立し、ビデオ ゲームで画像をレンダリングするチップを製造しました。当時の標準的なマイクロプロセッサは複雑な計算を順番に実行することに優れていましたが、Nvidia は複数の単純なタスクを同時に処理できる GPU を作りました。2006 年、ジェンセン フアンはこのプロセスをさらに一歩進めました。同氏は、GPU が新しいタスク向けにプログラムされるのを支援する CUDA と呼ばれるソフトウェア テクノロジをリリースし、GPU を単一用途のチップから、物理学や化学のシミュレーションなどの分野で他の仕事を引き受けることができるより汎用的なチップに変換しました。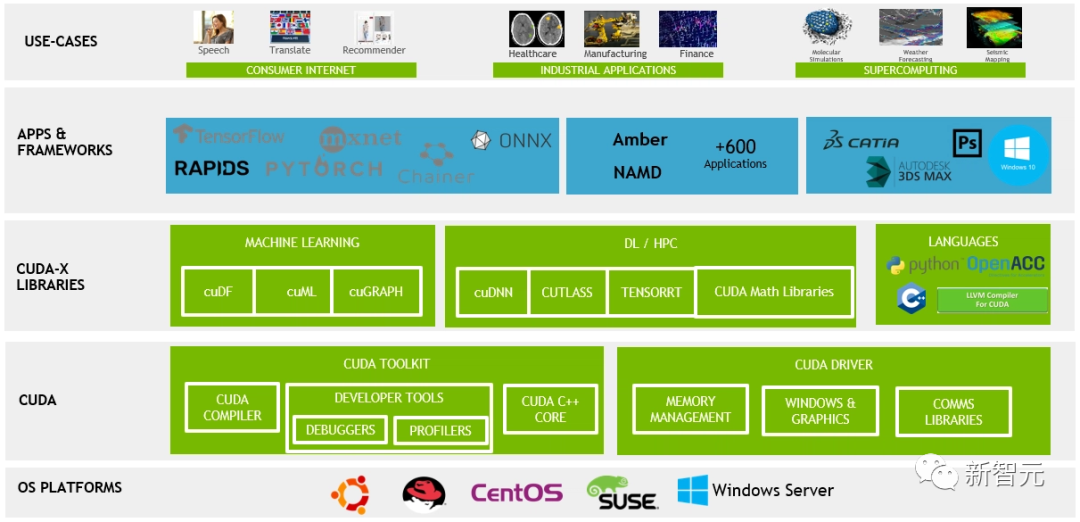 2012 年、研究者らは GPU を使用して、画像内の猫の識別などのタスクで人間と同等の精度を達成しました。これは大きな進歩であり、テキスト キューから画像を生成するなどの最近の開発の先駆けとなりました。Nvidia はこの取り組みに 10 年間で 300 億ドル以上かかると見積もっており、Nvidia を単なる部品サプライヤー以上の存在にしています。同社は、一流の科学者や新興企業との協力に加え、言語モデルの作成やトレーニングなどの AI 活動に直接関与するチームを編成しました。さらに、実務家のニーズにより、Nvidia は CUDA を超えた複数層の主要なソフトウェアを開発するようになりました。これには、数百行の事前構築コードのライブラリも含まれていました。ハードウェア面では、Nvidia は 2 ~ 3 年ごとに高速チップを継続的に提供することで評判を得ています。 2017 年、Nvidia は特定の AI 計算を処理できるように GPU のチューニングを開始しました。昨年 9 月、Nvidia は、いわゆる Transformer 操作を処理できるように改良された、H100 と呼ばれる新しいチップを生産していると発表しました。このような計算は、Huang 氏が生成人工知能の「iPhone モーメント」と呼んだ ChatGPT などのサービスの基礎であることが証明されています。 現在、他のメーカーの製品が Nvidia の GPU と積極的な競争を形成できない限り、AI コンピューティング能力における Nvidia の現在の独占を打破することは可能です。IBMのアナログAIチップでも可能でしょうか?参考文献:


Nvidia H100の覇権に挑戦! IBMが人間の脳の人工ニューラルネットワークチップをシミュレート、効率を14倍向上させ、AIモデルの消費電力問題を解決
出典: 新志源
最近、IBM は、最新の 14nm アナログ AI チップを発売しました。これは、主要な GPU よりも 14 倍効率が高く、H100 にお金を払う価値があります。
現在、生成型 AI の開発における最大の障害は、その驚くべき消費電力です。 AI に必要なリソースは持続的に成長することができません。
一方、IBMはAIコンピューティングを再構築する方法を研究してきた。彼らの成果の 1 つは、生物学的な脳内で実行されるニューラル ネットワークの主要な機能を使用してエネルギー消費を削減できる、模擬メモリ コンピューティング/模擬人工知能手法です。
このアプローチにより、計算に費やす時間と労力が最小限に抑えられます。
Nvidia の独占は覆されようとしていますか?
海外メディアInsiderの報道によると、半導体調査会社セミアナリシスの首席アナリスト、ディラン・パテル氏は、ChatGPTの1日の運用コストが70万ドルを超えていると分析した。
ChatGPT は、ユーザーのプロンプトに基づいて回答を生成するために多くのコンピューティング能力を必要とします。コストのほとんどは高価なサーバーで発生します。
将来的には、モデルのトレーニングとインフラストラクチャの運用にかかるコストはますます高騰するでしょう。
これらのアナログ チップは、アナログ信号を操作して 0 と 1 の間の勾配を理解できるデジタル チップとは異なる方法で構築されていますが、異なるバイナリ信号のみを認識します。
シミュレートされたメモリ コンピューティング/シミュレートされた AI
そして、IBM の新しいアプローチは、メモリ コンピューティング、略して AI をシミュレートすることです。生物学的な脳で動作するニューラル ネットワークの重要な機能を利用することで、エネルギー消費を削減します。
人間や他の動物の脳では、シナプスの強さ(または「重さ」)がニューロン間の通信を決定します。
アナログ AI システムの場合、IBM はこれらのシナプスの重みをナノメートルスケールの抵抗メモリデバイス (相変化メモリ PCM など) のコンダクタンス値に保存し、回路の法則を使用してメモリとメモリの間でデータを常に送信する必要性を減らします。プロセッサは、DNN の主要な演算である積和演算 (MAC) 演算を実行します。
現在、多くの生成 AI プラットフォームを支えているのは、Nvidia の H100 と A100 です。
しかし、IBMがチップのプロトタイプを繰り返し、大衆市場への投入に成功すれば、この新しいチップがNvidiaに取って代わる新たな主力となる可能性は十分にあります。
また、このチップは人間の脳の仕組みを模倣しており、マイクロチップがメモリ内で直接計算を実行します。
このチップのシステムは、デジタル ハードウェアに近い精度で、効率的な音声認識と転写を実現できます。
このチップは約 14 倍の性能を達成しており、以前のシミュレーションでは、このハードウェアのエネルギー効率は今日の主要な GPU の 40 倍から 140 倍であることが示されています。
この生成 AI 革命はまだ始まったばかりです。ディープ ニューラル ネットワーク (DNN) は AI 分野に革命をもたらし、基本モデルと生成 AI の開発によって注目を集めてきました。
ただし、これらのモデルを従来の数学的コンピューティング アーキテクチャで実行すると、パフォーマンスとエネルギー効率が制限されます。
AI 推論用のハードウェアの開発は進んでいますが、これらのアーキテクチャの多くはメモリと処理ユニットを物理的に分離しています。
これは、AI モデルが通常、個別のメモリの場所に保存され、コンピューティング タスクではメモリと処理ユニットの間でデータを絶えずシャッフルする必要があることを意味します。このプロセスにより計算が大幅に遅くなり、達成できる最大のエネルギー効率が制限される可能性があります。
IBM の相変化メモリ (PCM) ベースの人工知能加速チップは、この制限を取り除きます。
相変化メモリ (PCM) は、計算と記憶の統合を実現し、メモリ内で行列とベクトルの乗算を直接実行できるため、データ転送の問題を回避できます。
同時に、IBMのアナログAIチップは、ハードウェアレベルのコンピューティングとストレージの統合を通じて効率的な人工知能推論の高速化を実現しており、これはこの分野における重要な進歩である。
AI のシミュレーションにおける 2 つの主要な課題
シミュレートされた AI の概念を実現するには、次の 2 つの重要な課題を克服する必要があります。
メモリ アレイの計算精度は、既存のデジタル システムの計算精度に匹敵する必要があります。
メモリ アレイは、他のデジタル コンピューティング ユニットおよびアナログ人工知能チップ上のデジタル通信構造とシームレスにインターフェイスできます。
IBM は、アルバニー ナノにあるテクノロジー センターで相変化メモリ ベースの人工知能アクセラレータ チップを製造しています。
このチップは 64 個のアナログ メモリ コンピューティング コアで構成され、各コアには 256×256 個のクロスストリップ シナプス ユニットが含まれています。
また、各チップには、アナログ世界とデジタル世界の間で変換するためのコンパクトな時間ベースのアナログ - デジタル コンバーターが統合されています。
チップ内の軽量デジタル処理ユニットは、単純な非線形ニューロン活性化関数とスケーリング操作も実行できます。
各コアは、ディープ ニューラル ネットワーク (DNN) モデルの層 (畳み込み層など) に関連付けられた行列ベクトル乗算やその他の操作を実行できるタイルと考えることができます。
重み行列は、PCM デバイスのシミュレートされたコンダクタンス値にエンコードされ、オンチップに保存されます。
グローバル デジタル処理ユニットはチップのコア アレイの中央に統合されており、特定の種類のニューラル ネットワーク (LSTM など) の実行にとって重要な行列ベクトル乗算よりも複雑な演算を実装します。
デジタル通信パスは、コア間およびコアとグローバル ユニット間のデータ転送のために、すべてのコアとグローバル デジタル処理ユニットの間でオンチップに統合されています。
b: 64 コア、8 つのグローバル デジタル プロセッシング ユニット、コア間のデータ リンクを含む、チップのさまざまなコンポーネントの概略図
c: 単一の PCM ベースのインメモリ コンピューティング コアの構造
d: LSTM 関連計算のためのグローバルデジタル処理ユニットの構造
このチップを使用して、IBM はアナログ メモリ コンピューティングの計算精度に関する包括的な研究を実施し、CIFAR-10 画像データセットで 92.81% の精度を達成しました。
b: このネットワークをチップ上にマッピングする方法
c: ハードウェア実装の CIFAR-10 テスト精度
これは、同様のテクノロジーを使用したチップとしてこれまでに報告されている最高の精度です。
IBM はまた、アナログ インメモリ コンピューティングと複数のデジタル処理装置およびデジタル通信構造をシームレスに組み合わせます。
このチップの 8 ビット入出力行列乗算の単位面積スループットは 400 GOPS/mm2 で、これは抵抗メモリに基づく以前のマルチコア メモリ コンピューティング チップよりも 15 倍以上高く、同時にかなりのエネルギー効率も達成します。
文字予測タスクと画像アノテーション生成タスクにおいて、IBMはハードウェア上で測定した結果を他の方法と比較し、シミュレートされたAIチップ上で実行される関連タスクのネットワーク構造、重み付けプログラミング、および測定結果を実証しました。
**NVIDIA の堀は底なし? **
Nvidia の独占はそんなに簡単に崩れるのでしょうか?
ナヴィーン・ラオは、神経科学から転向したテクノロジー起業家で、世界有数の人工知能メーカーである Nvidia と競争しようとしました。
「誰もが Nvidia で開発を行っています。新しいハードウェアを発売したい場合は、Nvidia に追いつき、競争する必要があります。」とラオ氏は述べました。
ラオ氏は、インテルが買収した新興企業で Nvidia の GPU を置き換えるように設計されたチップの開発に取り組んでいましたが、Intel を辞めた後は、自身が率いるソフトウェア スタートアップ企業 MosaicML で Nvidia のチップを使用しました。
Rao 氏は、Nvidia はチップ上で他の製品との大きな差を広げただけでなく、AI プログラマーの大規模なコミュニティを創設することでチップの外側でも差別化を達成したと述べました。
AI プログラマーは同社のテクノロジーを活用して革新を続けています。
かつて業界の新興企業だった同社が AI チップ製造分野で優位性を達成できたのは、AI のトレンドを早くから認識し、それらのタスク用にカスタム構築したチップを開発し、AI 開発を促進する重要なソフトウェアを開発したためです。
それ以来、Nvidia の共同創設者兼 CEO の Jensen Huang は、Nvidia の水準を引き上げてきました。
Google、Amazon、Meta、IBMなどもAIチップを製造しているが、調査会社Omdiaによると、現在AIチップの売上高の70%以上をNvidiaが占めているという。
今年6月、NVIDIAの市場価値は1兆ドルを超え、世界で最も価値のあるチップメーカーとなった。
NVIDIA、コンピューティング手法を再構築
ジェンセン フアンは 1993 年に Nvidia を共同設立し、ビデオ ゲームで画像をレンダリングするチップを製造しました。当時の標準的なマイクロプロセッサは複雑な計算を順番に実行することに優れていましたが、Nvidia は複数の単純なタスクを同時に処理できる GPU を作りました。
2006 年、ジェンセン フアンはこのプロセスをさらに一歩進めました。同氏は、GPU が新しいタスク向けにプログラムされるのを支援する CUDA と呼ばれるソフトウェア テクノロジをリリースし、GPU を単一用途のチップから、物理学や化学のシミュレーションなどの分野で他の仕事を引き受けることができるより汎用的なチップに変換しました。
Nvidia はこの取り組みに 10 年間で 300 億ドル以上かかると見積もっており、Nvidia を単なる部品サプライヤー以上の存在にしています。同社は、一流の科学者や新興企業との協力に加え、言語モデルの作成やトレーニングなどの AI 活動に直接関与するチームを編成しました。
さらに、実務家のニーズにより、Nvidia は CUDA を超えた複数層の主要なソフトウェアを開発するようになりました。これには、数百行の事前構築コードのライブラリも含まれていました。
ハードウェア面では、Nvidia は 2 ~ 3 年ごとに高速チップを継続的に提供することで評判を得ています。 2017 年、Nvidia は特定の AI 計算を処理できるように GPU のチューニングを開始しました。
昨年 9 月、Nvidia は、いわゆる Transformer 操作を処理できるように改良された、H100 と呼ばれる新しいチップを生産していると発表しました。このような計算は、Huang 氏が生成人工知能の「iPhone モーメント」と呼んだ ChatGPT などのサービスの基礎であることが証明されています。
IBMのアナログAIチップでも可能でしょうか?
参考文献: