#### 要約* アップルのCEOティム・クックは、AI駆動の需要が同社の予測を大きく超えたため、Mac miniとMac Studioは「数か月間」品薄のままである可能性があると警告した。* OpenClaw—OpenAIが後援するオープンソースのAIエージェントプラットフォーム—は、アップルの統合メモリアーキテクチャを大規模なローカルAIモデルを実行するための標準ハードウェアに変えた。* アップルのM4 Ultraは最大192GBの統合メモリをサポートし、消費者向けNvidia GPUの最大32GBのVRAMに収まらないモデルを実行できるようにしている。アップルのMac miniは、いつも静かで目立たないデスクトップとしてアップルストアの奥に置かれていた。実用的でアップル基準では安価であり、AI界隈からはほとんど無視されてきた。そこにOpenClawが登場した。木曜日、ティム・クックはアナリストに対し、Mac miniとMac Studioは完売しており、数か月間その状態が続く可能性があると述べた。「これらはAIやエージェントツールにとって素晴らしいプラットフォームであり」と彼はアップルの2026年第2四半期決算説明会で語った。「そして、その認知度は私たちの予測よりも早く高まっている。」翻訳:アップルは、特に市場が逼迫している時にこれらのマシンをどれほど欲しがるかを見誤っていた。今四半期のMacの売上は84億ドルで、前年同期比6%増だった。大きなヒットではないが、供給制約が需要ではなく制限要因だ。高RAMのMac miniとMac Studioの構成は遅れるだけでなく、一部はアップルストアから完全に撤去されている。<span style="width:0px;overflow:hidden;line-height:0" data-mce-type="bookmark" class="mce_SELRES_start"></span>米国では599ドルのベースMac miniは完売し、配送や店頭受取はできない。64GBのRAMを搭載したアップグレード版は、待ち時間が16〜18週間と表示されている。512GBの統合メモリを搭載したMac Studioモデルは、店頭から完全に姿を消した。eBayの転売業者はすぐに気づき、ベースモデルをほぼ定価の2倍近くで出品している。これらすべてのきっかけは?OpenClawとメモリを大量に必要とするエージェントAIのブームだ。オープンソースのAIエージェントフレームワークは、ピーター・スタインバーガーによって構築され、Metaとの入札戦争の末にOpenAIが後援し、GitHubのスター数は32万3千を超え、個人や小規模チームがローカルで持続的なAIエージェントを実行する最速の方法となった。そして、それを動かす非公式のリファレンスハードウェアは、ほぼ即座にMac miniとなった。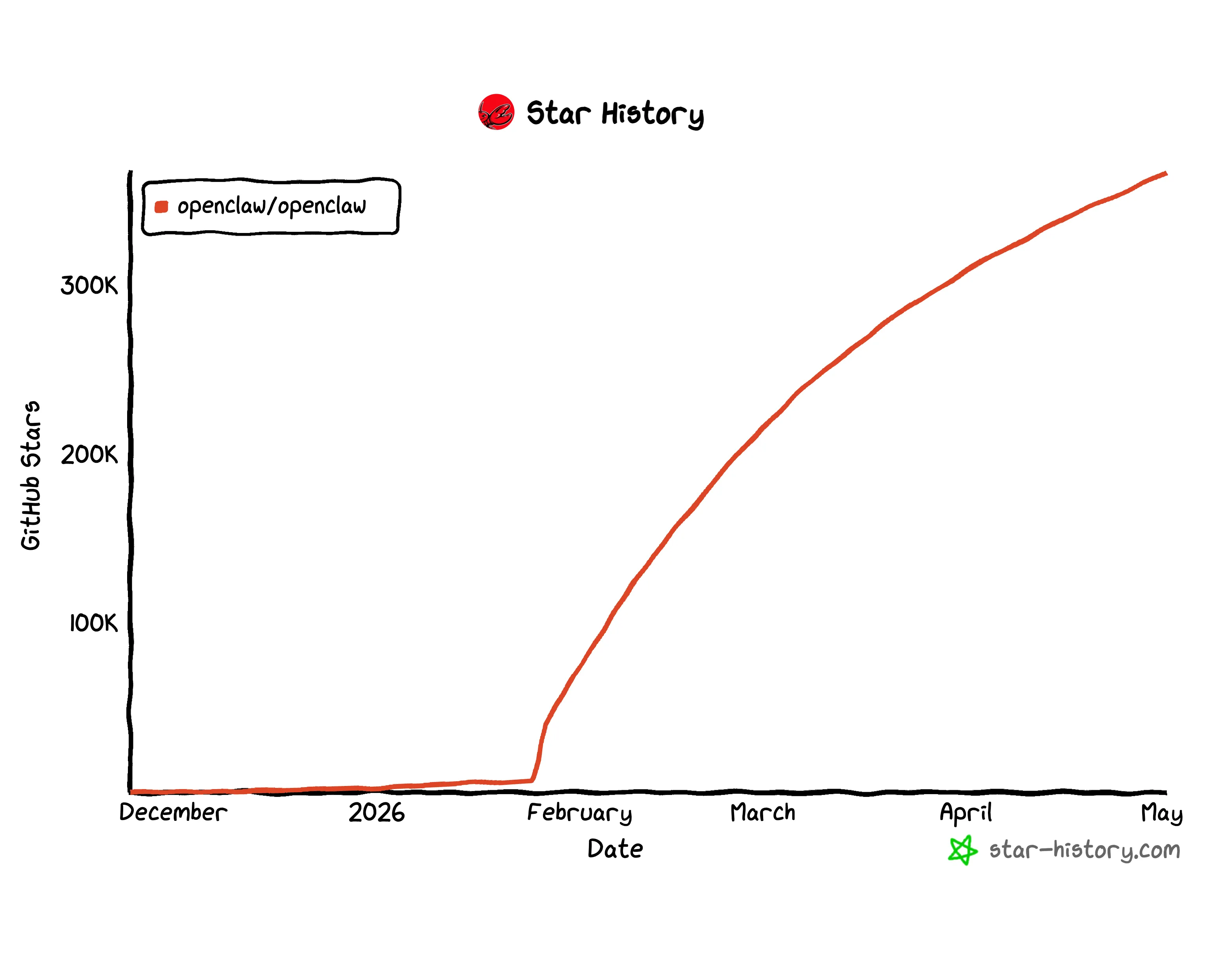しかし、これはマーケティングの成果ではなかった。多くの人がMac不足を報じる中で見落としがちなのは、アップルは長年、真剣なAIワークロードには無関係だったという事実だ。AIエージェントが主流になり始める前、人々はLLMやStable Diffusion、その他の家庭用AIソフトウェアの動作が非常に遅く、ほとんど使い物にならないと不満を漏らしていた。M2 Macの性能は2019年のGPUとほぼ同等だった。アップルがCUDAを採用せず、Nvidiaを使わず、MLX技術を推進したことで、AIにとってもゲームにとっても無関係な存在になっていた。Nvidiaが支配的だったのは、CUDA—独自のGPUプログラミングフレームワーク—がモデルの訓練と推論の基盤だったからだ。AIの全スタックはそれを中心に構築されていた。アップルにはそれに匹敵するものはなかった。誰もローカル推論のためにMacを欲しがらなかった。しかし、CUDAには隠された秘密がある:VRAMの制限だ。最も優れた消費者向けNvidia GPU、RTX 5090は、VRAMが32GBで頭打ちだ。これが硬い上限だ。32GBを超える大きなモデルは、そのカードではフルスピードで動作できず、システムの遅いRAMに spill し、PCIeバスを横断し、パフォーマンスが大きく低下する。Nvidiaハードウェアで70億パラメータの本格的なモデルを動かすには、複数のGPU、サーバラック、相当な電力消費、そして何千ドルも必要だ。アップルの統合メモリアーキテクチャ(UMA)は、CUDAにはできない解決策を提供する。Apple Silicon上では、CPU、GPU、ニューラルエンジンがすべて同じ物理的なメモリプールを共有している。VRAMは存在しない。PCIeバスを横断する必要もない。64GBのMac miniは、1800ドルのRTX 5090が触れさえしない70億パラメータのモデルをロードできる。M4 Ultraは、ハイエンドのMac Studio構成を動かすチップで、最大192GBの統合メモリをサポートしている。これは、1台のマシンで1000億パラメータのモデルをローカルで実行できることを意味する。サーバもクラウドの月額料金も不要だ。OpenClawはこのトレードオフを明らかにした。エージェントをローカルで動かし、ファイルやアプリ、メッセージに接続するため、ユーザーはクラウドから計算資源を借りることなく推論負荷を処理できるマシンを必要とした。32GBの統合メモリを持つMac miniは30Bパラメータのモデルを快適に動かせる。128GBのMac Studioは、かつては企業用GPUクラスターなしでは触れられなかったモデルを扱える。パワフルなAIモデルを動かせる遅いMacは、そのモデルを全くロードできない強力なNvidiaカードよりもはるかに価値がある。その結果、開発者はMac miniを買い始めた。かつてのRaspberry Piのように、複数台をインフラとして扱い、個人用PCではなくインフラとして購入するようになった。アップルのサプライチェーンは、そのパターンに対応できるように設計されていなかった。さらに、より広範なメモリ不足も問題を悪化させている。IDCは、2026年の世界のPC出荷台数が11.3%減少すると予測しており、その一因はAIサーバー需要によるメモリチップ不足だ。アップルもまた、データセンターを構築するハイパースケーラーと同じRAM供給を争っている。クックは、Mac miniとStudioの供給と需要のバランスを取るのに「数か月」かかる可能性があると述べた。2026年後半にはM5チップのリフレッシュも予定されており、これが圧力を緩和する可能性があるが、現時点の購入者は待つか、スキャルパー価格を支払うしかない。Mac miniは、20年の歴史の中でこれまで以上に緊急性を高めており、そのすべては、アップルが全く関係のなかったオープンソースプロジェクトの助けを借りて実現したのだった。
OpenClawがAppleをAIゲームに再び引き戻す—そして今や彼らはMacを追いつくのが間に合わない
要約
アップルのMac miniは、いつも静かで目立たないデスクトップとしてアップルストアの奥に置かれていた。実用的でアップル基準では安価であり、AI界隈からはほとんど無視されてきた。そこにOpenClawが登場した。 木曜日、ティム・クックはアナリストに対し、Mac miniとMac Studioは完売しており、数か月間その状態が続く可能性があると述べた。「これらはAIやエージェントツールにとって素晴らしいプラットフォームであり」と彼はアップルの2026年第2四半期決算説明会で語った。「そして、その認知度は私たちの予測よりも早く高まっている。」 翻訳:アップルは、特に市場が逼迫している時にこれらのマシンをどれほど欲しがるかを見誤っていた。
今四半期のMacの売上は84億ドルで、前年同期比6%増だった。大きなヒットではないが、供給制約が需要ではなく制限要因だ。高RAMのMac miniとMac Studioの構成は遅れるだけでなく、一部はアップルストアから完全に撤去されている。 米国では599ドルのベースMac miniは完売し、配送や店頭受取はできない。64GBのRAMを搭載したアップグレード版は、待ち時間が16〜18週間と表示されている。512GBの統合メモリを搭載したMac Studioモデルは、店頭から完全に姿を消した。eBayの転売業者はすぐに気づき、ベースモデルをほぼ定価の2倍近くで出品している。 これらすべてのきっかけは?OpenClawとメモリを大量に必要とするエージェントAIのブームだ。
オープンソースのAIエージェントフレームワークは、ピーター・スタインバーガーによって構築され、Metaとの入札戦争の末にOpenAIが後援し、GitHubのスター数は32万3千を超え、個人や小規模チームがローカルで持続的なAIエージェントを実行する最速の方法となった。そして、それを動かす非公式のリファレンスハードウェアは、ほぼ即座にMac miniとなった。
しかし、これはマーケティングの成果ではなかった。 多くの人がMac不足を報じる中で見落としがちなのは、アップルは長年、真剣なAIワークロードには無関係だったという事実だ。AIエージェントが主流になり始める前、人々はLLMやStable Diffusion、その他の家庭用AIソフトウェアの動作が非常に遅く、ほとんど使い物にならないと不満を漏らしていた。M2 Macの性能は2019年のGPUとほぼ同等だった。アップルがCUDAを採用せず、Nvidiaを使わず、MLX技術を推進したことで、AIにとってもゲームにとっても無関係な存在になっていた。 Nvidiaが支配的だったのは、CUDA—独自のGPUプログラミングフレームワーク—がモデルの訓練と推論の基盤だったからだ。AIの全スタックはそれを中心に構築されていた。アップルにはそれに匹敵するものはなかった。誰もローカル推論のためにMacを欲しがらなかった。 しかし、CUDAには隠された秘密がある:VRAMの制限だ。 最も優れた消費者向けNvidia GPU、RTX 5090は、VRAMが32GBで頭打ちだ。これが硬い上限だ。32GBを超える大きなモデルは、そのカードではフルスピードで動作できず、システムの遅いRAMに spill し、PCIeバスを横断し、パフォーマンスが大きく低下する。Nvidiaハードウェアで70億パラメータの本格的なモデルを動かすには、複数のGPU、サーバラック、相当な電力消費、そして何千ドルも必要だ。 アップルの統合メモリアーキテクチャ(UMA)は、CUDAにはできない解決策を提供する。Apple Silicon上では、CPU、GPU、ニューラルエンジンがすべて同じ物理的なメモリプールを共有している。VRAMは存在しない。PCIeバスを横断する必要もない。64GBのMac miniは、1800ドルのRTX 5090が触れさえしない70億パラメータのモデルをロードできる。
M4 Ultraは、ハイエンドのMac Studio構成を動かすチップで、最大192GBの統合メモリをサポートしている。これは、1台のマシンで1000億パラメータのモデルをローカルで実行できることを意味する。サーバもクラウドの月額料金も不要だ。 OpenClawはこのトレードオフを明らかにした。エージェントをローカルで動かし、ファイルやアプリ、メッセージに接続するため、ユーザーはクラウドから計算資源を借りることなく推論負荷を処理できるマシンを必要とした。32GBの統合メモリを持つMac miniは30Bパラメータのモデルを快適に動かせる。128GBのMac Studioは、かつては企業用GPUクラスターなしでは触れられなかったモデルを扱える。 パワフルなAIモデルを動かせる遅いMacは、そのモデルを全くロードできない強力なNvidiaカードよりもはるかに価値がある。 その結果、開発者はMac miniを買い始めた。かつてのRaspberry Piのように、複数台をインフラとして扱い、個人用PCではなくインフラとして購入するようになった。アップルのサプライチェーンは、そのパターンに対応できるように設計されていなかった。 さらに、より広範なメモリ不足も問題を悪化させている。IDCは、2026年の世界のPC出荷台数が11.3%減少すると予測しており、その一因はAIサーバー需要によるメモリチップ不足だ。アップルもまた、データセンターを構築するハイパースケーラーと同じRAM供給を争っている。 クックは、Mac miniとStudioの供給と需要のバランスを取るのに「数か月」かかる可能性があると述べた。2026年後半にはM5チップのリフレッシュも予定されており、これが圧力を緩和する可能性があるが、現時点の購入者は待つか、スキャルパー価格を支払うしかない。 Mac miniは、20年の歴史の中でこれまで以上に緊急性を高めており、そのすべては、アップルが全く関係のなかったオープンソースプロジェクトの助けを借りて実現したのだった。