51.2万行代码,1906个文件,59.8MB的source map。3月31日凌晨,Solayer Labs的Chaofan Shou发现Anthropic的旗舰产品Claude Code把完整源码暴露在了公共npm仓库里。几小时内,代码被镜像到GitHub,fork数突破4.1万。
这不是Anthropic第一次犯这个错。2025年2月Claude Code首次发布时,同样的source map泄漏就发生过一次。这次的版本号是v2.1.88,泄漏原因相同,Bun构建工具默认生成source map,而.npmignore里漏掉了这个文件。
大部分报道在盘点泄漏里的彩蛋,比如有虚拟宠物系统,有“卧底模式”让Claude匿名给开源项目提交代码。但真正值得拆的问题是,为什么同一个Claude模型,在网页版和在Claude Code里表现差那么多?51.2万行代码到底在做什么?
模型只是冰山一角
答案藏在代码结构里。据GitHub社区对泄漏源码的逆向分析,51.2万行TypeScript中,直接负责调用AI模型的接口代码只有约8000行,占总量的1.6%。
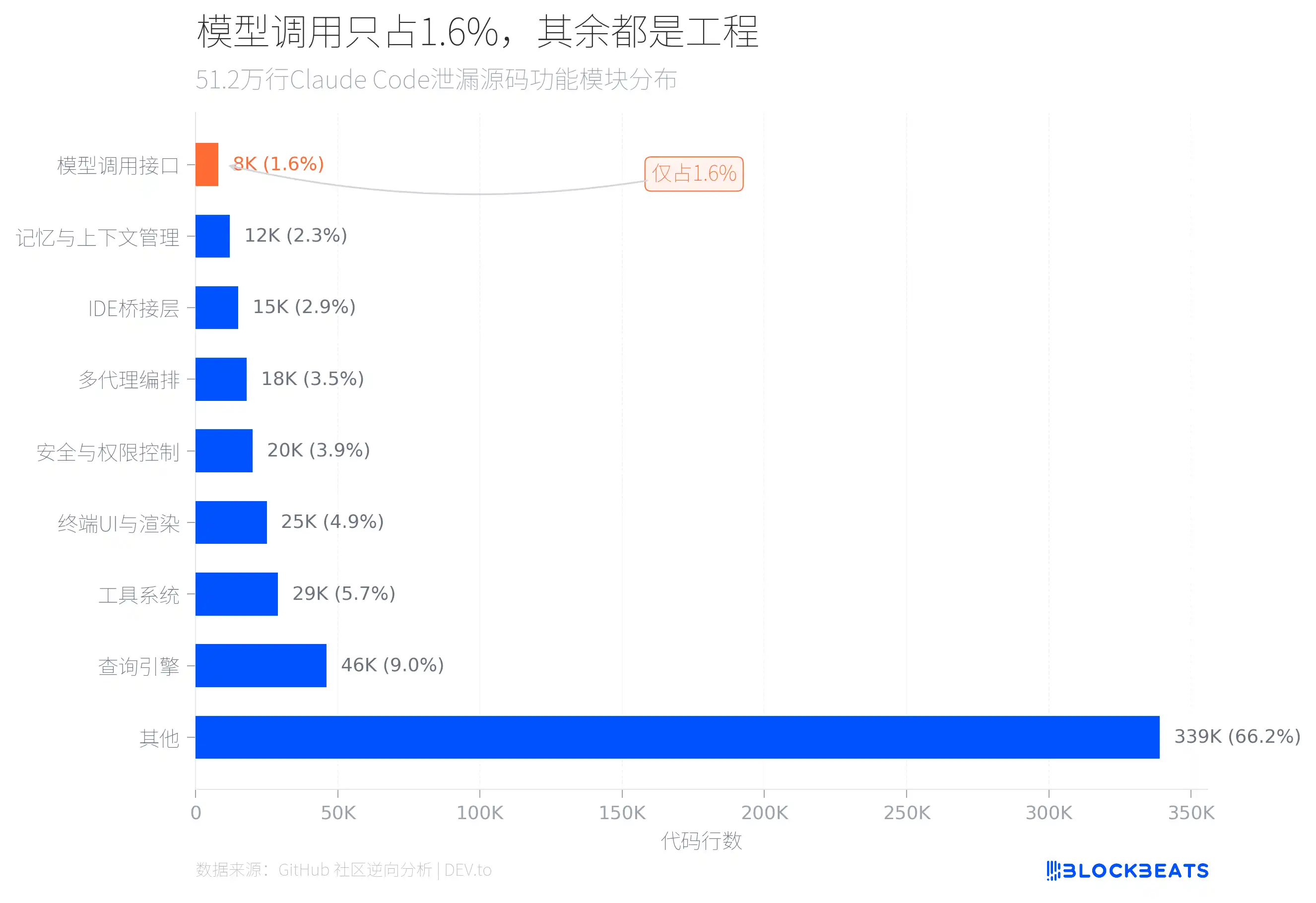
剩下的98.4%在做什么?最大的两个模块是查询引擎(4.6万行)和工具系统(2.9万行)。查询引擎处理LLM API调用、流式输出、缓存编排和多轮对话管理。工具系统定义了约40个内置工具和50个斜杠命令,形成了一套类插件架构,每个工具有独立的权限控制。
此外还有2.5万行的终端UI渲染代码(其中一个叫print.ts的文件长达5594行,单个函数跨越3167行),2万行的安全与权限控制(包含23项编号Bash安全检查和18个被屏蔽的Zsh内建命令),以及1.8万行的多代理编排系统。
机器学习研究者Sebastian Raschka在分析了泄漏代码后指出,Claude Code之所以比同模型的网页版强,核心不在模型本身,而在于围绕模型构建的软件脚手架,包括仓库上下文加载、专用工具调度、缓存策略和子代理协作。他甚至认为,如果把同样的工程架构套到DeepSeek或Kimi等其他模型上,也能获得接近的编程性能提升。
一个直观的对比可以帮助理解这种差距。你在ChatGPT或Claude网页版输入一个问题,模型处理完就返回答案,对话结束时什么都不留下。但Claude Code的做法完全不同,它启动时先读你的项目文件,理解你的代码库结构,记住你上次说过“不要在测试里mock数据库”这样的偏好。它能直接在你的终端里执行命令、编辑文件、运行测试,遇到复杂任务时还会拆成多个子任务分配给不同的子代理并行处理。换句话说,网页版AI是一个问答窗口,Claude Code是一个住在你电脑里的协作者。
有人把这套架构比作操作系统:42个内置工具相当于系统调用,权限系统相当于用户管理,MCP协议相当于设备驱动,子代理编排相当于进程调度。每个工具出厂时默认被标记为“不安全、可写入”,除非开发者主动声明它是安全的。编辑文件的工具会强制检查你是否先读过这个文件,没读过就不让改。这不是一个聊天机器人外挂了几个工具,而是一个以LLM为内核、带完整安全机制的运行环境。
这意味着一件事:AI产品的竞争壁垒,可能不在模型层,而在工程层。
每次缓存击穿,成本翻10倍
泄漏代码中有一个叫promptCacheBreakDetection.ts的文件,它追踪14种可能导致prompt cache失效的向量。为什么Anthropic的工程师要花这么多精力防止缓存击穿?
看一下Anthropic官方定价就明白了。以Claude Opus 4.6为例,标准输入价格是每百万token 5美元,但如果命中缓存,读取价格只要0.5美元,便宜90%。反过来说,每一次缓存击穿,推理成本就要翻10倍。
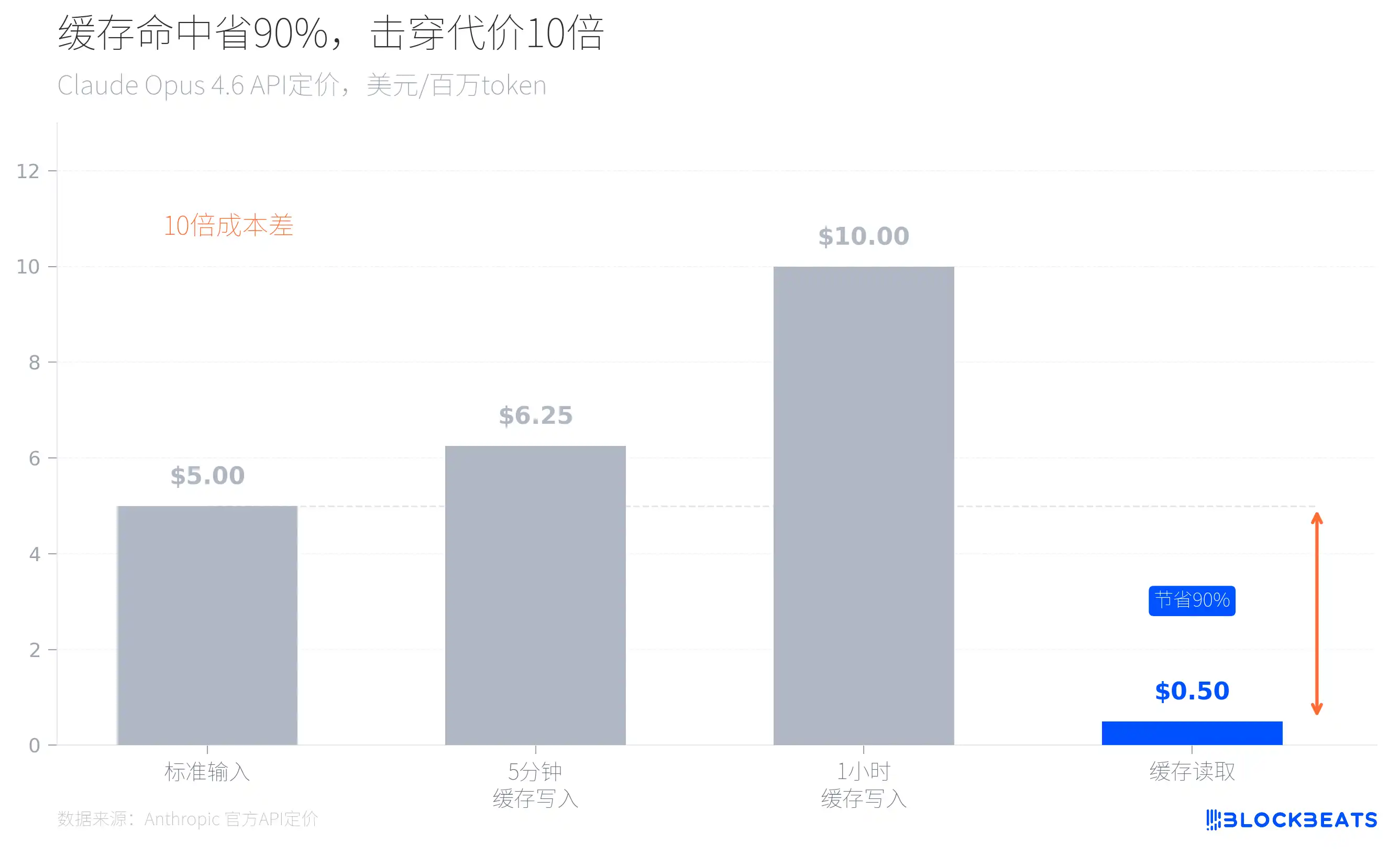
这解释了泄漏代码中大量看似“过度设计”的架构决策。Claude Code启动时会加载当前git分支、最近的commit记录和CLAUDE.md文件作为上下文,这些静态内容被全局缓存,用边界标记分隔动态内容,确保每次对话不会重复处理已有上下文。代码中还有一种叫sticky latches的机制,防止模式切换破坏已建立的缓存。子代理被设计为复用父进程的缓存,而不是重新建立自己的上下文窗口。
这里有一个值得展开的细节。用过AI编程工具的人都知道,对话越长,AI回复越慢,因为每一轮对话都要把前面的历史重新发送给模型。常规做法是删掉旧消息来释放空间,但问题是,删除任何一条消息都会打破缓存的连续性,导致整个对话历史需要重新处理,延迟和费用同时飙升。
泄漏代码中存在一个叫cache_edits的机制,做法是不真的删除消息,而是在API层给旧消息打上“跳过”标记。模型看不到这些消息了,但缓存的连续性没有被破坏。这意味着一段持续几小时的长对话,清理掉几百条旧消息之后,下一轮的响应速度和第一轮几乎一样快。对普通用户而言,这就是“为什么Claude Code能支持无限长对话而不变慢”的底层答案。
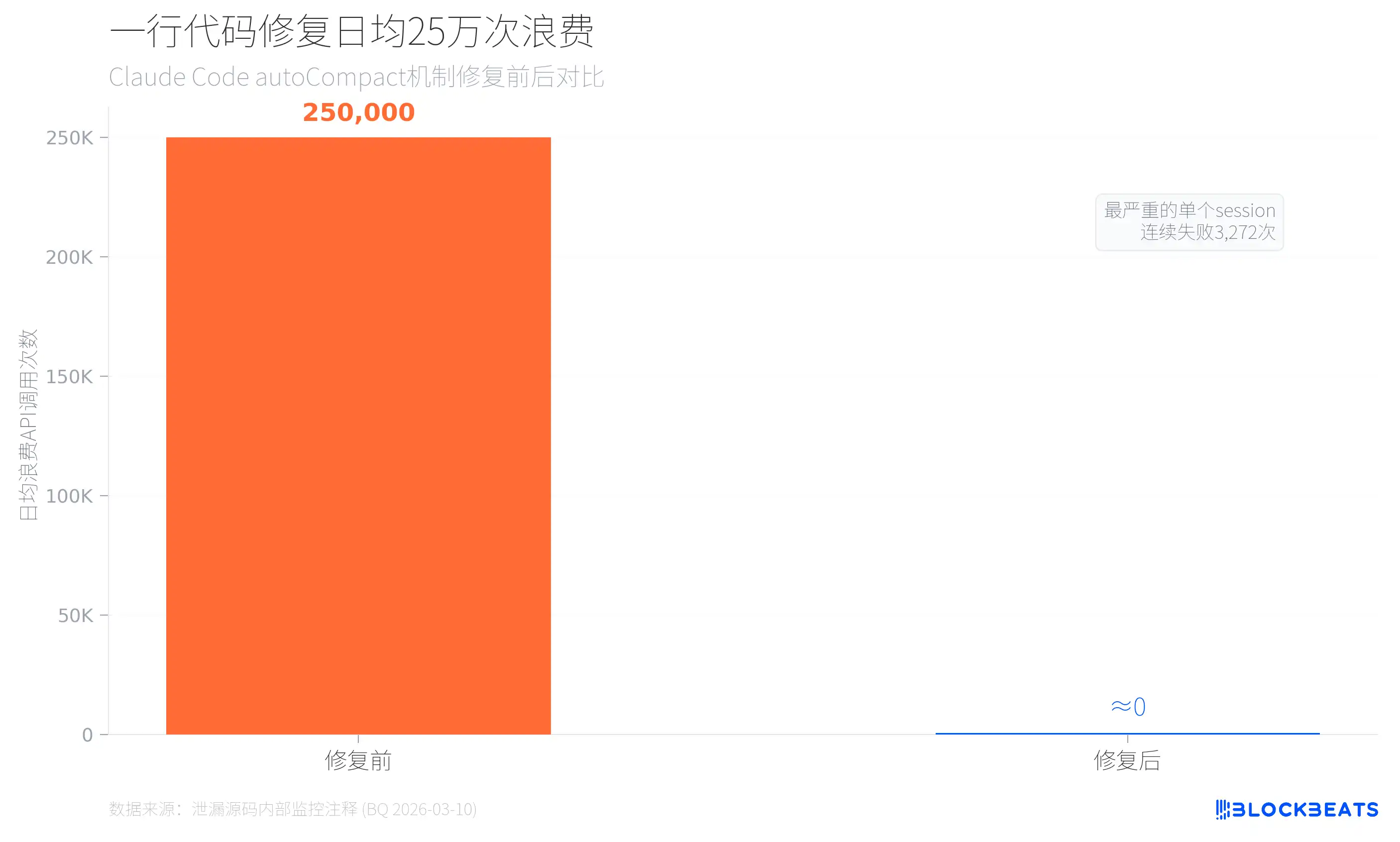
据泄漏的内部监控数据(来自autoCompact.ts的代码注释,标注日期2026年3月10日),在引入自动压缩失败上限之前,Claude Code每天浪费约25万次API调用。有1279个用户session出现了50次以上的连续压缩失败,最严重的一个session连续失败了3272次。修复方式只是加了一行限制:MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3。
所以,对于AI产品而言,模型推理成本可能不是最贵的那一层,缓存管理失败才是。
44个开关,指向同一个方向
泄漏代码中藏着44个feature flags——已经编译好的功能开关,只是没有对外发布。据社区分析,这些flags按功能域分为五类,其中最密集的是“自主代理”类(12个),指向一个名为KAIROS的系统。
KAIROS在源码中被引用超过150次,它是一个常驻后台守护进程模式。Claude Code不再只是你主动调用时才响应的工具,而是一个始终在后台运行的代理,持续观察、记录,并在合适的时机主动行动。前提是不打断用户,任何可能阻塞用户超过15秒的操作都会被延迟执行。
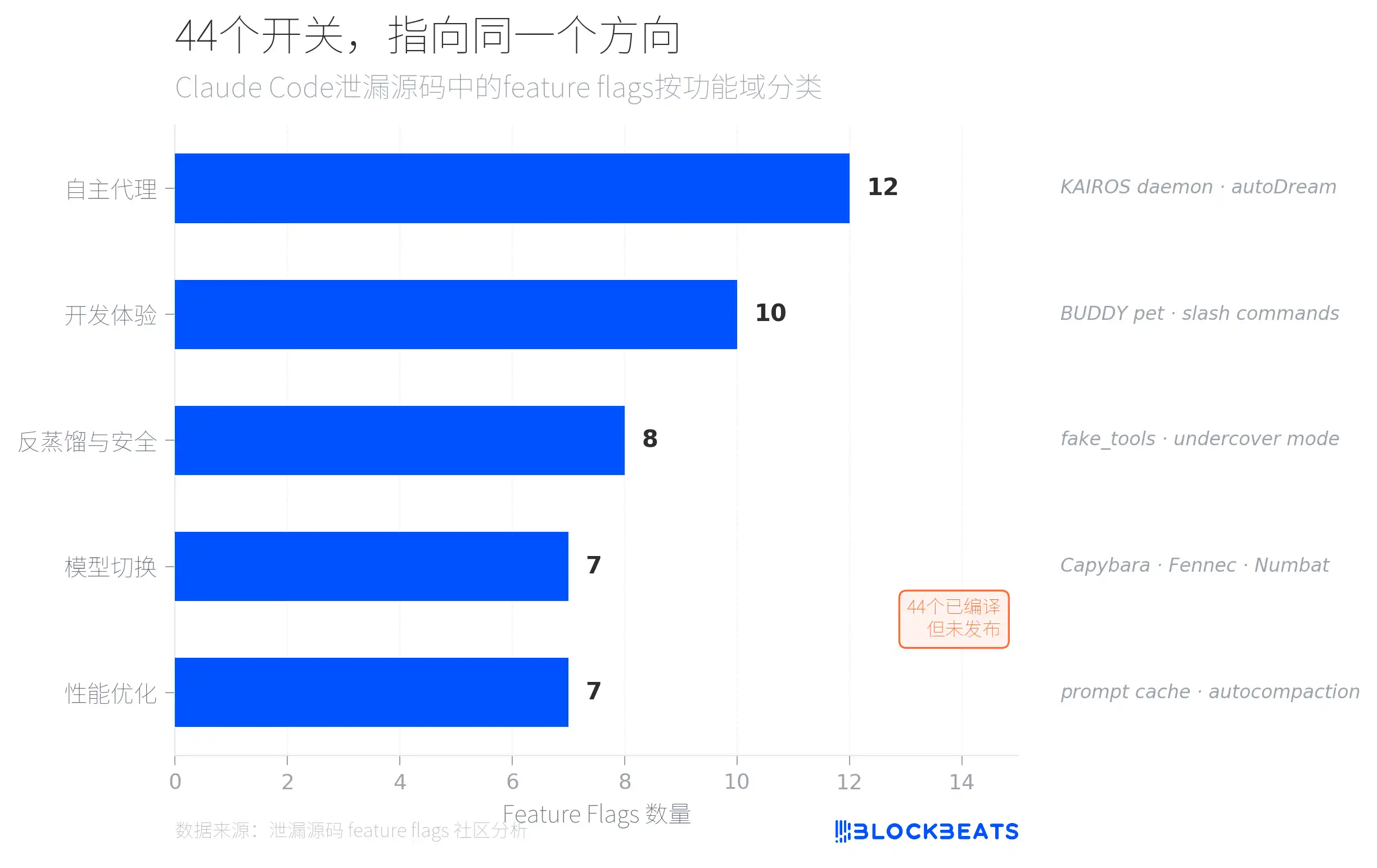
KAIROS还内置了终端焦点感知。代码中有一个terminalFocus字段,实时检测用户是否正在看终端窗口。当你切到浏览器或其他应用,代理判定你“不在”,会切换为自主模式,主动执行任务、直接提交代码、不等你确认。当你切回终端,代理立刻回到协作模式:先汇报刚才做了什么,再征求你的意见。自主程度不是固定的,而是跟着你的注意力实时浮动。这解决了一个AI工具长期以来的尴尬问题:完全自主的AI让人不放心,完全被动的AI效率又太低。KAIROS的选择是让AI的主动性随用户注意力动态调节,你盯着它就老实,你走开了它就自己干活。
KAIROS的另一个子系统叫autoDream,每累积5个会话或间隔24小时,代理会在后台启动一个“反思”流程,分四步走。先扫描已有记忆,了解自己目前掌握什么。再从对话日志里提取新知识。然后把新旧知识做合并,修正矛盾、去除重复。最后精简索引,删掉过时的条目。这个设计借鉴了认知科学中的记忆巩固理论。人在睡眠时整理白天的记忆,KAIROS在用户离开时整理项目上下文。对普通用户来说,这意味着你用Claude Code越久,它对你项目的理解就越精确,而不只是“记住你说过什么”。
第二大类是“反蒸馏与安全”(8个flags)。其中最值得注意的是fake_tools机制,当4个条件同时满足时(编译时flag开启、CLI入口激活、使用第一方API、GrowthBook远程开关为true),Claude Code会在API请求中注入假的工具定义,目的是污染可能在录制API流量、用于训练竞品模型的数据集。这是AI军备竞赛中一种全新的防御形态,不是阻止你抄,是让你抄到错误的东西。
此外,代码中还出现了Capybara模型代号(分为标准版、fast版和百万上下文窗口版三个层级),被社区广泛猜测为Claude 5系列的内部代号。
彩蛋:51.2万行代码里藏着一只电子宠物
在所有严肃的工程架构和安全机制之间,Anthropic的工程师还悄悄造了一套完整的虚拟宠物系统,内部代号BUDDY。
据泄漏代码和社区分析,BUDDY是一个拟物化的终端宠物,会以ASCII气泡框的形式出现在用户输入框旁边。它有18个物种(包括水豚、蝾螈、蘑菇、幽灵、龙,以及一系列原创生物如Pebblecrab、Dustbunny、Mossfrog),按稀有度分为五个等级:普通(60%)、罕见(25%)、稀有(10%)、史诗(4%)和传奇(1%)。每个物种还有“闪光变体”,最稀有的Shiny Legendary Nebulynx出现概率只有万分之一。
每只BUDDY有五项属性:DEBUGGING(调试)、PATIENCE(耐心)、CHAOS(混乱)、WISDOM(智慧)和SNARK(毒舌)。它们还能戴帽子,选项包括皇冠、礼帽、螺旋桨帽、光环、巫师帽,甚至还有一只迷你鸭子。用户ID的哈希值决定你会孵化出哪只宠物,Claude会为它生成名字和性格。
据泄漏的上线计划,BUDDY原定4月1日到7日开始内测,5月正式上线,先从Anthropic内部员工开始。
51.2万行代码,98.4%在做硬核工程,但最后有人花时间做了一只会戴螺旋桨帽的电子蝾螈。这或许才是泄漏里最人性化的那一行代码。
点击了解律动BlockBeats在招岗位
欢迎加入律动BlockBeats官方社群:
Telegram订阅群:https://t.me/theblockbeats
Telegram交流群:https://t.me/BlockBeats_App
Twitter官方账号:https://twitter.com/BlockBeatsAsia
إخلاء المسؤولية: قد تكون المعلومات الواردة في هذه الصفحة من مصادر خارجية ولا تمثل آراء أو مواقف Gate. المحتوى المعروض في هذه الصفحة هو لأغراض مرجعية فقط ولا يشكّل أي نصيحة مالية أو استثمارية أو قانونية. لا تضمن Gate دقة أو اكتمال المعلومات، ولا تتحمّل أي مسؤولية عن أي خسائر ناتجة عن استخدام هذه المعلومات. تنطوي الاستثمارات في الأصول الافتراضية على مخاطر عالية وتخضع لتقلبات سعرية كبيرة. قد تخسر كامل رأس المال المستثمر. يرجى فهم المخاطر ذات الصلة فهمًا كاملًا واتخاذ قرارات مدروسة بناءً على وضعك المالي وقدرتك على تحمّل المخاطر. للتفاصيل، يرجى الرجوع إلى
إخلاء المسؤولية.
